Chapter 6 Maps and Spatial Data
Chapter 6 reviews the use of geographic packages for drawing and analyzing data embedded in maps.
Learning objectives and chapter resources
By the end of this chapter, you should be able to (1) explain key characteristics of geospatial data for creating political maps; (2) identify and collect geospatial datafiles relevant to the study of politics; (3) apply tools in visualizing and analyzing geospatial data, analyzing the extent of gerrymandering in U.S. legislative districts. The material in the chapter requires the following packages to be installed: leaflet (Cheng, Karambelkar, and Xie 2023), leaflet.extras (Gatscha, Karambelkar, and Schloerke 2024), sf (Pebesma 2018; Pebesma and Bivand 2023), ggspatial (Dunnington 2023), cartogram (Jeworutzki 2023), and tidycensus (Walker and Herman 2024). For data preparation and labeling maps: dplyr (Wickham, François, et al. 2023) and ggplot2 (Wickham, Chang, et al. 2023) from the tidyverse (Wickham 2023b), which should already be installed. The material uses the following datasets michigan12_16.csv, Michigan_State_Senate_Districts_2011_plan.geojson, ZAF_ADM4.geojson, Crime_Incidents_in_2024.geojson, and Counties__v17a.shp from https://faculty.gvsu.edu/kilburnw/inpolr.html.
6.1 Maps as data
Maps and the visualization of data associated with political boundary lines are of inherent interest to the study of politics. The chapter begins with a brief overview of key terminology in the analysis of data with geographic characteristics. From there we apply these principles in the creation of maps visualizing political phenomena, such as election results, leading to the study of ‘gerrymandering’, the practice of drawing legislative districts to benefit one party over another.
The use of geospatial data requires some unusual assumptions about how the data was collected and what visually it represents. For example, these assumptions involve underlying models of how latitude and longitude coordinates are determined, and how a particular geographic area of the three-dimensional earth gets represented on a two-dimensional image. The discussion below is necessarily brief, providing an overview of essential ideas for identifying, cleaning, and combining geographic data. For a more in-depth discussion and application to more advanced methods of analysis, see Lovelace, Nowosad, and Muenchow (2019) and Walker (2023).
The term “geospatial” or “spatial data” refers to a particular type of data, information to identify the geographic location and characteristics of natural and man-made features around the world, from rivers and mountain ranges to political boundaries and election results. Geospatial information is organized into two broad types, vector and raster.
Vector data is the type more common in political science research; it is used to represent particular geometries such as points, lines, and polygons that in turn represent political phenomena of interest. For example, points could represent the location of people or cities, lines for roads, and polygons for the shape of political entities such as legislative districts. Raster data is relatively uncommon in the study of politics. A “raster” refers to a grid or matrix of cells (imagine screen pixels), each containing a value that represents a specific attribute, such as elevation or temperature. To make sense of the data, each of these geometric entities usually has “attribute data” attached, such as the name of the city, road, or political boundary. Attribute data are characteristics of the geographies that are not part of defining the geography itself, such as the number of registered Republican or Democratic voters in a legislative district.
Key terms in geospatial data
The terms and underlying assumptions about a “datum”, “ellipse”, and “projection” require brief explanation. A “datum” is a reference model of the earth’s shape, used as the basis for the coordinate system of latitude and longitude. The datum is based on a particular mathematical model of the “ellipse”, the three-dimensional representation of the earth’s shape upon which the coordinates are developed. From a starting point in this model, the northerly or southerly location (latitude) and easterly or westerly location (longitude) coordinates are developed.
In working with geospatial data, you will often see reference to “North American Datum of 1983 (NAD83)” or more likely the “World Geodetic System of 1984 (WGS84)”. The WGS 84 determines the reference coordinate system used by Global Positioning System (GPS) tools. Most geospatial data available for download on the web will use this datum. Ideally, data collected from a different datum intended to be combined should be placed on the same datum, but this step is really only necessary for a high degree of precision or map resolution.
The cardinal directions North, South, East, and West correspond to particular coordinate designations. For latitude, coordinates in the Northern hemisphere coordinates are recorded with an N and Southern coordinates with an S; for longitude, Eastern hemisphere with an E and Western hemisphere with a W. In place of cardinal directions, positive coordinate numbers are used for N and negative coordinate numbers for S — similarly, an E with a positive coordinate number and W with a negative coordinate number.
Map projection
A projection refers to a particular way of taking geographic features on the curved three-dimensional surface of Earth and ‘projecting’ or translating it onto a two-dimensional flat image. Like taking a curved piece of paper with an image of North America and flattening it, parts of the paper will have to fold over onto itself, distorting the original curved image. Different projections will distort different aspects of the map (like area, shape, or distance) to a greater or lesser extent. For an analysis involving measurements like distance or geographic area, or when working with large areas, it is usually necessary to consider projection. Without a proper projection, measurements can be inaccurate without accounting for the curvature of the Earth.
To illustrate differences between projections, Figure 6.1 presents two different projections of the continental USA. The first is a Mercator projection. The Mercator projection, in the upper panel of Figure 6.1, is a projection prioritizing navigation (think driving directions), but notice the distorted straight line across the USA-Canada border and the distorted shapes of States near it. Below it is the “Albers Equal-Area Conic Projection”, which more closely preserves area and shape of the States at the expense of navigation. While less useful for navigating, the map projection features States with a more familiar shape and accurate area.
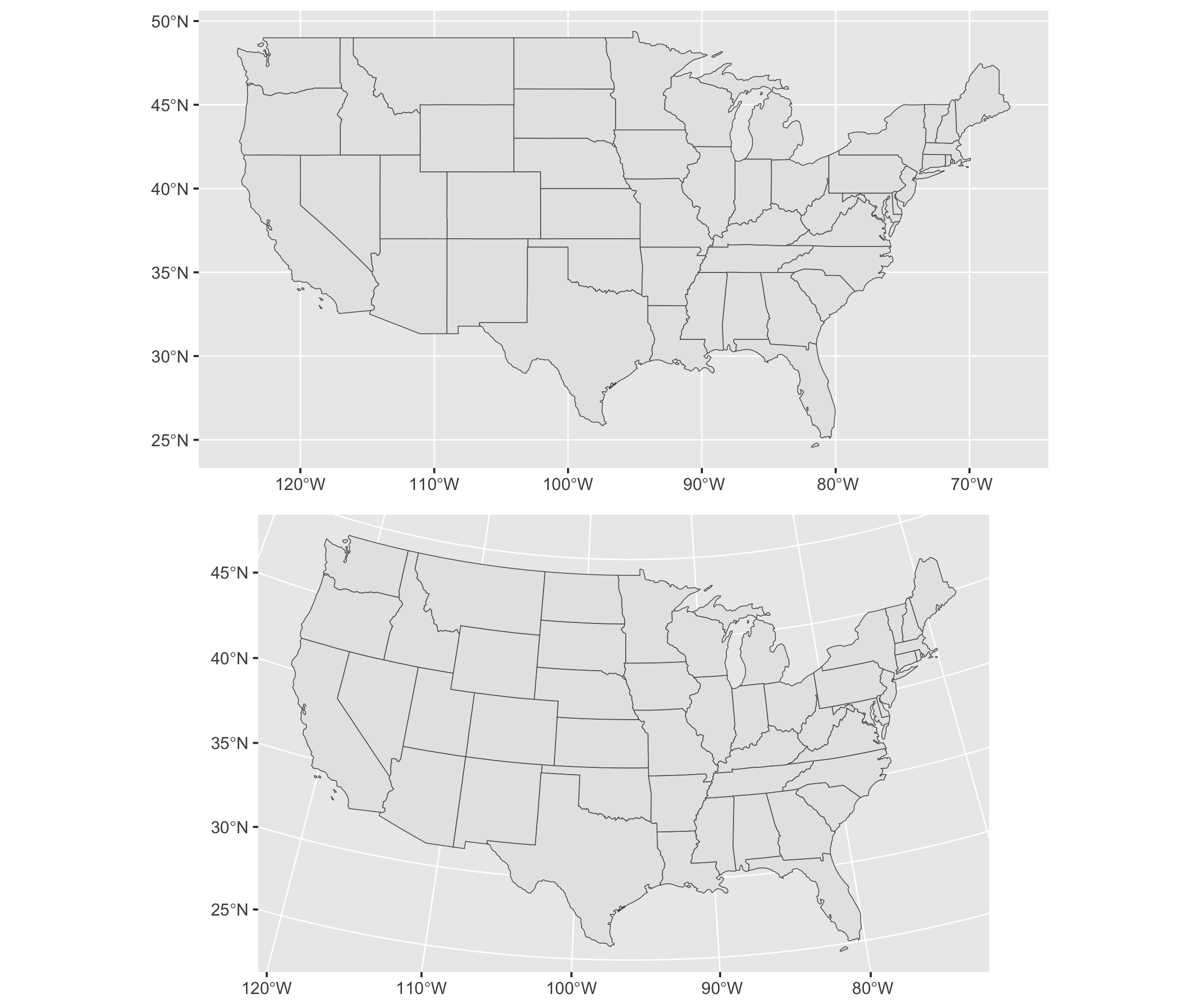
FIGURE 6.1: Comparison of two map projections for the continental United States. The upper panel uses the Mercator projection, while the lower panel uses the Albers Equal-Area Conic projection. These maps illustrate how projection choice affects the visual representation of geography.
Geospatial datafile formats
In searching for your own spatial data — vector data for displaying points, lines, or polygons — there are two commonly found formats.
A “Shapefile” refers to a set of files in a format originally developed by ESRI, a geographic information systems company. The Shapefile itself consists of not just one .shp (‘shape’) file, but also additional helper files including .shx, .dbf (for storing attribute data), and .prj. When working with Shapefiles, these three ancillary files are necessary and should be downloaded with the .shp file, all of which are usually made available in a .zip file archive. Shapefiles are relatively easy to find for the creation of vector maps, such as legislative boundary lines and voting precincts.
A “GeoJSON” file refers to the organization of the spatial data into a JSON file, the same as reviewed in Chapter 3. A single .geojson file may contain both geographic and attribute data sometimes referred to as “properties” of the geographic datafile. Because it is a single self-contained file and relatively smaller in file size, data analysts often prefer to work with GeoJSON over the “Shapefile” format.
Key steps and the big picture of maps and spatial data analysis
Constructing maps to analyze data tied to geographic features typically involves four basic steps.
Locating and downloading relevant geospatial datafiles, such as a .geojson file outlining legislative districts. If needed, make changes to the map projection; if combining multiple map files together as map layers (discussed further below), verify that each layer references the same datum and projection.
Locating or organizing any additional attribute data, characteristics of the geographic features (such as votes cast within a State) that are the focus of the analysis.
Merging the geospatial and attribute data, associating the attribute data with relevant geographic features.
Transforming and visualizing the attribute data within the geography.
In the sections that follow, we first review constructing maps, starting with the creation of interactive maps of political phenomena, then we will create static image maps.
6.2 Visualizing polygons and points
In working through Chapter 6, note that mapping packages are large in file size and time-consuming to download. Drawing maps requires much more computing power, along with much more patience until the maps show up in the Plots or Viewer pane of RStudio. So to make these analyses more feasible, the maps and geospatial data in the chapter usually focus on just one particular U.S. State, Michigan, or small areas with relatively few geographic features.
The functionality of interactive maps, such as maps that allow immediate panning or zooming on different areas or altering the data displayed on a map, is created through the leaflet (Cheng, Karambelkar, and Xie 2023) package and accessed through the “Viewer” pane (lower right of RStudio). The map interactivity is limited to this Viewer pane or, to view interactive maps outside of RStudio, the maps can be exported to an HTML file and hosted on a web server. The interactive maps cannot be embedded within a Microsoft Word document or PDF. So there is a tradeoff: while interactive maps allow for exploration of geographic features, this interactivity is limited to RStudio or webpages.
A basic interactive map using leaflet starts with the leaflet() function, which will require a geographic location to display in the map. One way to set the location of the map is by simply specifying latitude and longitude coordinates. The setView() function asks for both latitude (lat=) and longitude (lng=), and a level of focus or ‘zoom’, zoom =. A simple interactive map can be drawn with these two lines, followed by a third function, addTiles() which will draw the ‘tiles’ or image squares of the map.
If necessary, install leaflet (install.packages("leaflet")). To draw a map centered around Cape Town, South Africa, longitude is set to 18.6 degrees and latitude to -34 degrees:
The map will appear in the Viewer pane on the lower right-hand side of RStudio as in Figure 6.2, based on map data from OpenStreetMaps16. Using the mouse to pan the map in different directions, and the plus and minus signs to zoom in and out, the map can focus on any arbitrary area. The limiting scope of an interactive map of this kind is the attribute data provided by a researcher. As an additional layer to the map, a researcher can add any additional geospatial and attribute data of political interest.
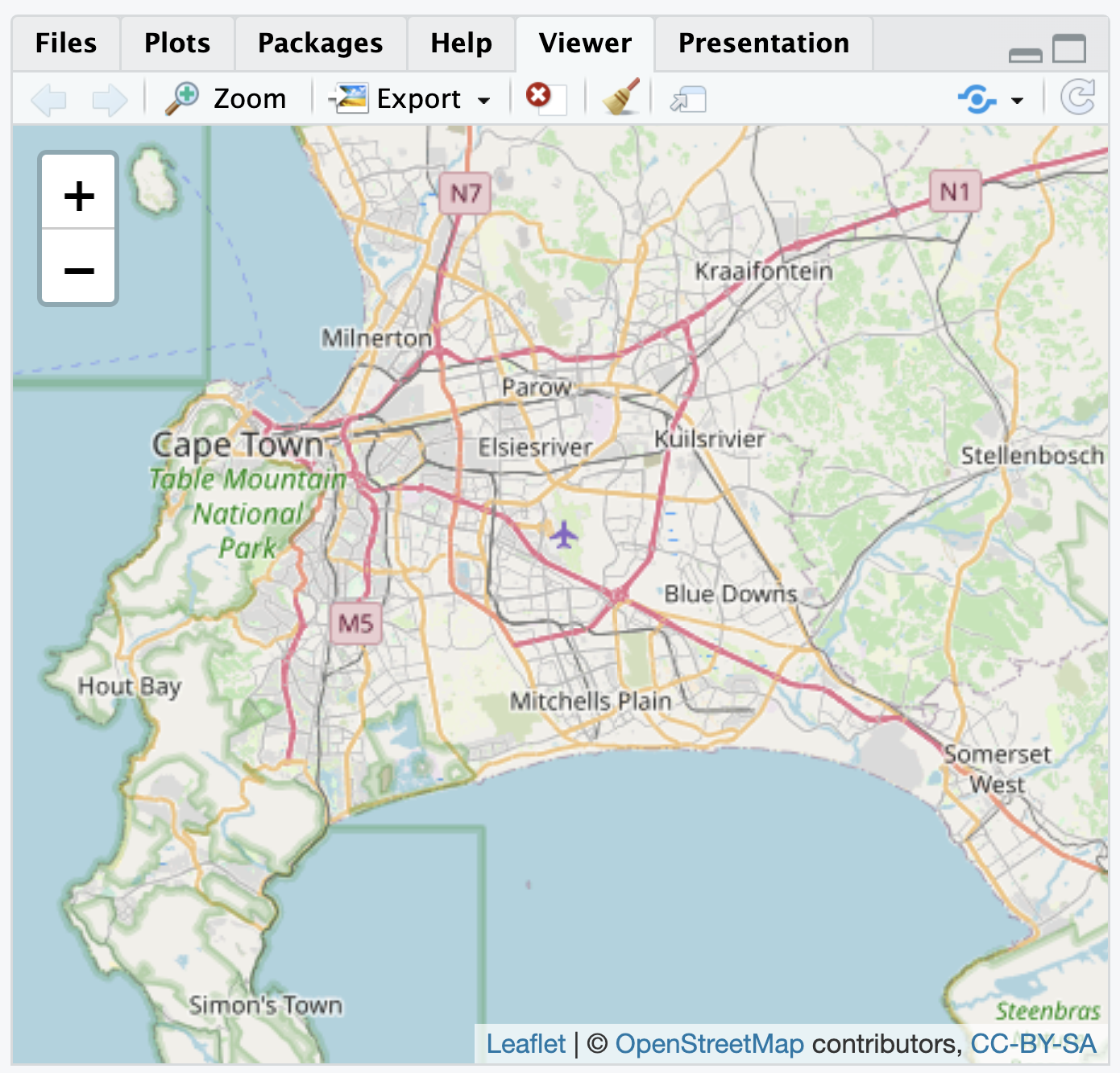
FIGURE 6.2: Interactive map of Cape Town, South Africa, with OpenStreetMap tiles as the base layer, as displayed in the Viewer pane.
Visualizing political boundaries
For example, some political boundaries are viewable through the interactive map, but perhaps over Cape Town a researcher plans to visualize other more detailed political boundaries and characteristics of each. The GeoQuery app at AidData.org17 makes available a wide range of geospatial data for state administrative units; one such set of units is the lowest level of administrative units for South Africa, recorded in the .geojson file ZAF_ADM4.geojson (Goodman et al. 2019).
From the sf package, the st_read() function will interpret the geospatial data, and with the assignment operator <- we create a map object sa_admin_boundaries. Soon after importing the data, we will clean it with the dplyr package.
## Reading layer `ZAF_ADM4' from data source
## `/Users/kilburnw/Documents/ZAF_ADM4.geojson'
## using driver `GeoJSON'
## Simple feature collection with 4392 features and 8 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: 16.45 ymin: -34.83 xmax: 32.94 ymax: -22.13
## Geodetic CRS: WGS 84After reading in the .geojson file, the function reports on the contents: (1) a map or ‘Simple feature collection’ of 4392 features, the administrative units throughout South Africa; (2) eight fields, or eight columns for each of the row administrative units within the file, plus an id or identification column; (3) the geometry type of multiple shapes or polygons, described in a coordinate system within a ‘bounding box’ or map with those four corners.
The goal in this example is to map out each of these administrative units on the interactive map of Cape Town. The map object sa_admin_boundaries contains the administrative units for all of South Africa. After entering glimpse(sa_admin_boundaries) you will see the column shapeName names the polygon based on location in a particular village or city.
To identify the rows corresponding to Cape Town, we can filter() on the rows in which the words “Cape Town” appear, overwriting the map data sa_admin_boundaries with only those rows. In Chapter 5 we used the filter() command to test whether a particular variable contained an exact character string or numeric value, but in this case shapeName contains both the name of the location and the number of the administrative unit, so filter(shapeName=="Cape Town") would not work. Instead, we want to find any rows containing at least the string “Cape Town”. The str_detect() function will find rows containing a string (returning a TRUE if the string is present in a row), and within filter() those rows will be selected for inclusion in the sa_admin_boundaries dataframe. Thus, we filter on rows where str_detect(shapeName, "City of Cape Town") are TRUE:
Because we have imported the map boundary file with st_read(), leaflet will automatically read the geometry column and locate the map boundaries, centering the boundaries in the map Viewer. The boundaries are polygons, so we add the boundary map with the function addPolygons():
The administrative ward polygons should appear as in Figure 6.3. At the default scale, the boundary lines obscure the map features; zoom in to see how the lines divide up the city.
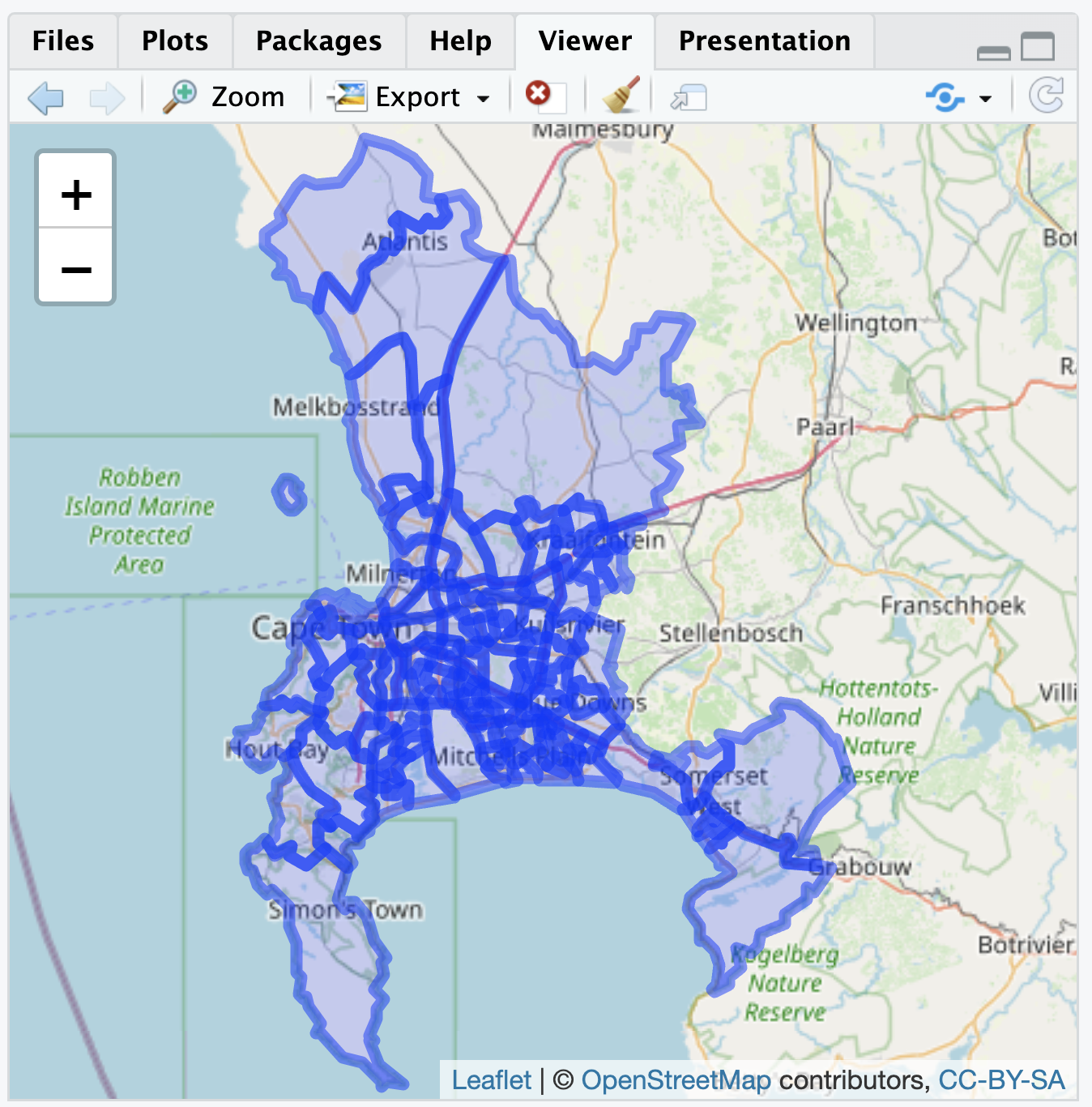
FIGURE 6.3: Interactive map of Cape Town, South Africa, displaying polygon boundaries of administrative units, with OpenStreetMap tiles as the base layer.
Earlier we briefly reviewed the concept of map projection, transforming spatial data from the three-dimensional Earth to a two-dimensional map. Although we are combining two different sources of geospatial data in Figure 6.3, when adding map layers to leaflet() it is usually not necessary to alter a map projection. With the additional layer located in latitude and longitude on the common WGS84 datum, leaflet() will line up the map layers correctly. Leaflet, like other ‘map tile’ apps such as Google Maps, uses a specific projection known as “Pseudo-Mercator” or “EPSG 3857”. For a relatively small area such as wards in Cape Town, distortions introduced by the Mercator projection are generally minimal and often unnoticeable. Nonetheless, for calculations involving area and distance where precision matters, the projection should be reconsidered for maximal accuracy.
By default, leaflet() draws the polygon shapes with a slight hue to show the extent of the polygon coverage over the map. Thus beyond the borders of each administrative unit, the polygons do not contain any additional data. We use variation in the shading of the borders to display additional data. For example, AidData.org provides a measure of fine particulate air pollution averaged to each polygon.
Visualizing boundary line attributes
The air pollution data measures PM2.5 concentration, measured in the year 2011, averaged to each administrative unit (Brauer et al. 2016). (The 2.5 in PM 2.5 refers to the size of the pollutant, in micrometers, such as from wildfire smoke, power plants or factory emissions.) When selected for downloading from AidData, the air pollution data is stored as a data table CSV, separated from the geospatial data. As characteristics of the polygons, the air pollution data can be treated as ‘attribute data’, and needs to be merged with the administrative unit boundaries. The first step is to import it and subset it to Cape Town.
The air pollution dataset, stored within RStudio as the dataframe sa_air_pollution consists of eight columns. Review the contents with glimpse(sa_air_pollution). The air pollution level is recorded in column ambient_air_pollution_2013_fus_calibrated.2011.mean. Like the data for administrative units, the column shapeName describes the geographic location, with each row corresponding to the different boundaries for an administrative ward. We will subset the data to Cape Town, as done previously:
To visualize the air pollution data, we need to merge it with the polygon data. The column ShapeName matches the same ShapeName column in the map data, so we will use that one for merging and displaying the differences in air pollution levels. All rows of the datafiles match with only one row of the other. While there are a few different merges that can be used, we will use inner_join() to merge the air pollution data onto the sa_admin_boundaries dataset:
Run glimpse(sa_admin_boundaries) to see how the dataset has changed. The air pollution data is appended onto the administrative boundaries. Duplicate column names are marked by the suffix .x (from sa_admin_boundaries) and .y (from sa_air_pollution). Notice the lengthy name for the measure of air pollution. We will change it to something simpler, such as air_pollution_level:
sa_admin_boundaries<-sa_admin_boundaries %>%
rename(air_pollution_level =
ambient_air_pollution_2013_fus_calibrated.2011.mean)To plot the variation in polygon color to display levels of air pollution, we need to first specify a color palette to display the variation in color. The function for doing so is colorNumeric().
Then we plot the data as follows, after filtering out missing values, storing the complete data in filtered_boundaries:
filtered_boundaries <- sa_admin_boundaries %>%
filter(!is.na(air_pollution_level))
leaflet(filtered_boundaries) %>%
addPolygons(fillColor=~pal(air_pollution_level), fillOpacity = .8,
weight = 0.5, ) %>%
addTiles() %>%
addLegend(pal = pal, values = ~air_pollution_level,
title = "2.5 air pollution levels", position = "bottomright")
The leaflet map will appear similar to Figure 6.4. Within addPolygons() the argument fillColor() links to the color palette for the levels of air_pollution_level. The boundary lines are further reduced to half their original size with weight=.5.
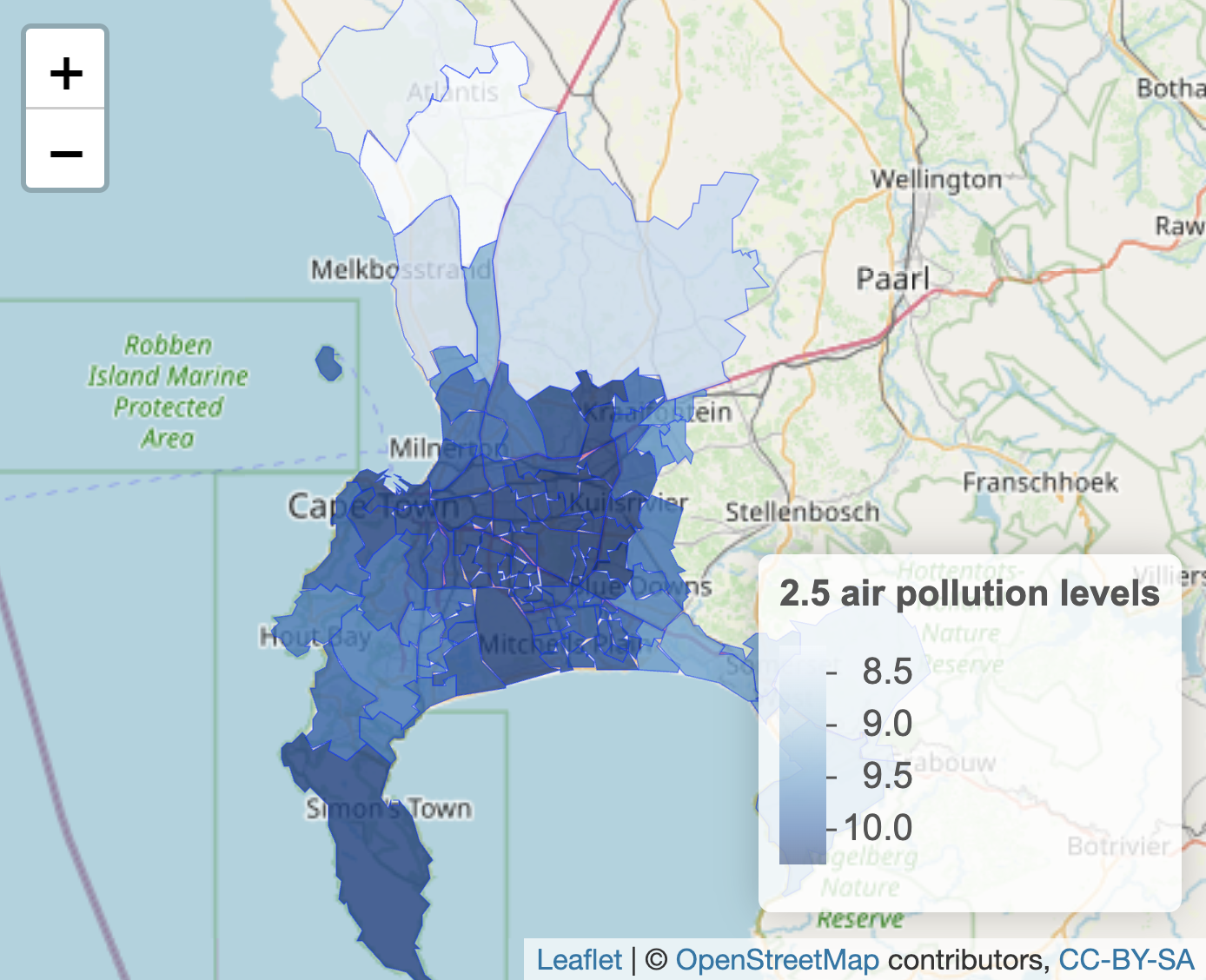
FIGURE 6.4: Interactive map of Cape Town, South Africa, displaying polygon boundaries of administrative units, shaded by fine particulate air pollution levels (PM2.5), with OpenStreetMap tiles as the base layer.
Visualizing points and point densities
Rather than embedded within boundary lines, data can be represented by points and visualized on a map. Each point must be measured in latitude and longitude. For a small number of points, the coordinates can be organized into a small dataset. (The process of translating street address locations into coordinates — geocoding — requires additional packages or other resources, described in the Resources section.)
In identifying point coordinates, you may return more precision than is needed. For example, Google Maps identified the location of the USA Consulate in Cape Town in decimal degree form at “-34.0768110805937,18.4296571685817”, which is a location with far more precision than necessary. As a rough rule of thumb for accuracy or precision, at one decimal place a location is accurate to within 10 kilometers, at two decimal places 1 kilometer, at three decimal places 100 meters, and at four decimal places 10 meters. So within 100 meters, we could say the USA Consulate is located 34.077 degrees south of the equator (-34.077) and 18.430 degrees east of the Prime Meridian (18.430). Thus for most purposes two to three decimal places is sufficient.
Given the coordinates, just one descriptive field for each point may be sufficient to plot the points on a map. The tribble() function from the tibble (Müller and Wickham 2023) package facilitates row-wise data entry. As a simple example, we could plot the location of three state consulates for the USA, China, and Russia. Latitude and longitude should be organized into two different columns, and we will need at least a third column to record the name of each one. In the tribble() function, the data elements are organized row-wise with the first row reserved for variable names preceded by a tilde ~ symbol. In this example, we record the latitude in a variable lat, longitude in long, and the name of the consulate in a variable name. The simplest storage type decision is to record character strings in quotes, while the coordinates will automatically be recorded in numeric form.
The tribble() contents of this function are assigned to a small dataset, three_consulates.
three_consulates<-tribble(
~lat, ~long, ~name,
-33.979,18.445,"Chinese Consulate",
-33.920,18.424, "Russian Consulate",
-34.077,18.430, "American Consulate")In entering the data with tribble(), each row (until the last one) ends with a comma, and the closed parenthesis completes the function. As a dataset it appears as a 3 by 3 table:
## # A tibble: 3 × 3
## lat long name
## <dbl> <dbl> <chr>
## 1 -34.0 18.4 Chinese Consulate
## 2 -33.9 18.4 Russian Consulate
## 3 -34.1 18.4 American ConsulateFor legibility, the resulting tibble prints only the first decimal of coordinates, but the full coordinates are saved within the dataset. The three_consulates layer can be added to any map as an additional layer. Figure 6.5 displays the consulates over the base map; the function addCircleMarkers() identifies the three_consulates dataframe coordinates and a label. The points could be added to the map of administrative unit polygons as an additional layer after addPolygons().
leaflet( ) %>%
addTiles() %>%
addCircleMarkers(lat=three_consulates$lat, lng=three_consulates$long,
label = three_consulates$name) 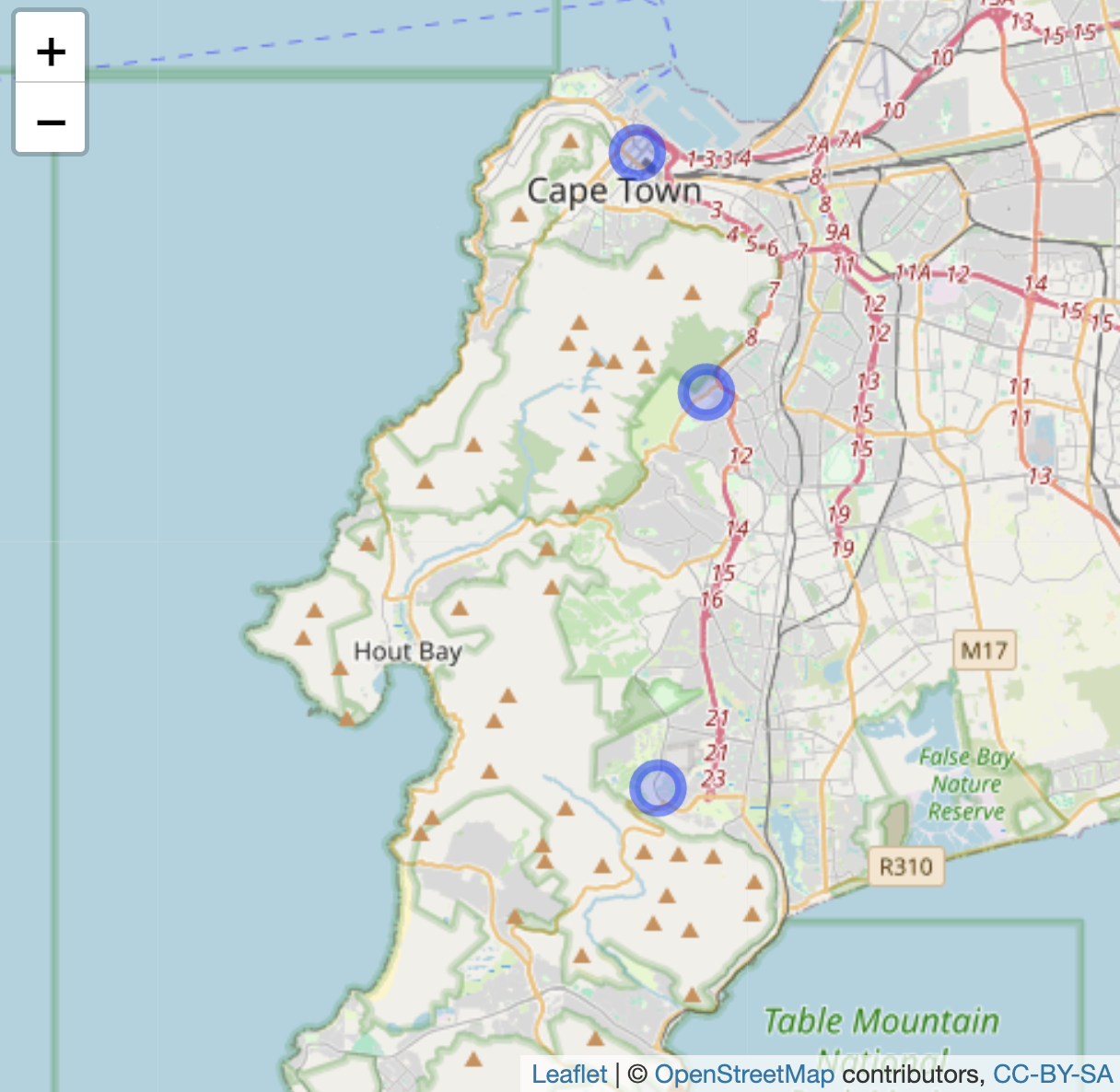
FIGURE 6.5: Interactive map of Cape Town, South Africa, with OpenStreetMap tiles as the base layer, displaying three point markers based on latitude and longitude coordinates.
Visualizing point densities
Data represented by points could be visualized discretely, as individual points, or if points are sufficiently numerous, as densities or ‘heatmaps’ that show trends over geographic areas. For example, data.gov hosts crime reports from the Washington, DC, Metropolitan Police (Open Data DC 2024). The .geojson file Crime_Incidents_in_2024.geojson contains crimes reported through the fall of 2024, each one geocoded to a particular location.
The variable OFFENSE records types of crimes. See the codebook for details. One level of OFFENSE is HOMICIDE. Subset the data to homicides:
Coordinates are recorded in variables LONGITUDE and LATITUDE. Each geocoded homicide can be plotted individually through addCircleMarkers(), or the density of each event through addHeatmap() from the leaflet.extras package (Gatscha, Karambelkar, and Schloerke 2024). To plot the points, we first set the boundaries of the leaflet map, centered around downtown DC, then addCircleMarkers():
leaflet() %>%
setView(lng = -77.0369, lat = 38.9072, zoom = 12) %>%
addTiles() %>%
addCircleMarkers(data = homicide_data, lng = ~LONGITUDE,
lat = ~LATITUDE, color = "red", radius = 2)The upper panel in Figure 6.6 displays the point map, each circle corresponding to a single homicide. The function argument radius=2 sets the point radius to two pixels. The points appear to cluster around the areas south of Anacostia and Columbia Heights. A heatmap helps to communicate the trends in the clusters. After installing the leaflet.extras package if necessary (install.packages("leaflet.extras")), we can plot the points through addHeatmap():
library(leaflet.extras)
leaflet() %>%
setView(lng = -77.0369, lat = 38.9072, zoom = 12) %>%
addTiles() %>%
addHeatmap(data = homicide_data, lng = ~LONGITUDE, lat = ~LATITUDE,
blur = 20, max = 0.05, radius = 15)The heatmap in the lower panel of Figure 6.6 focuses on clusters rather than individual events, and it does reveal a focal point south of Anacostia. Within addheatmap(), the three last arguments — blur=, max=, and radius= — affect how the map represents density patterns. The radius sets the size of the area around each point (measured in pixels) that contributes to the heatmap; larger values result in smoother, more generalized density patterns, while smaller values keep the density tightly localized to each point’s immediate vicinity. The blur option controls how sharply the density transitions from the center of a point to the edges of its radius. The max option sets the scaling for the density intensity, defining how bright or “hot” the most dense areas will appear. Try adjusting the arguments to observe how each affects the map.
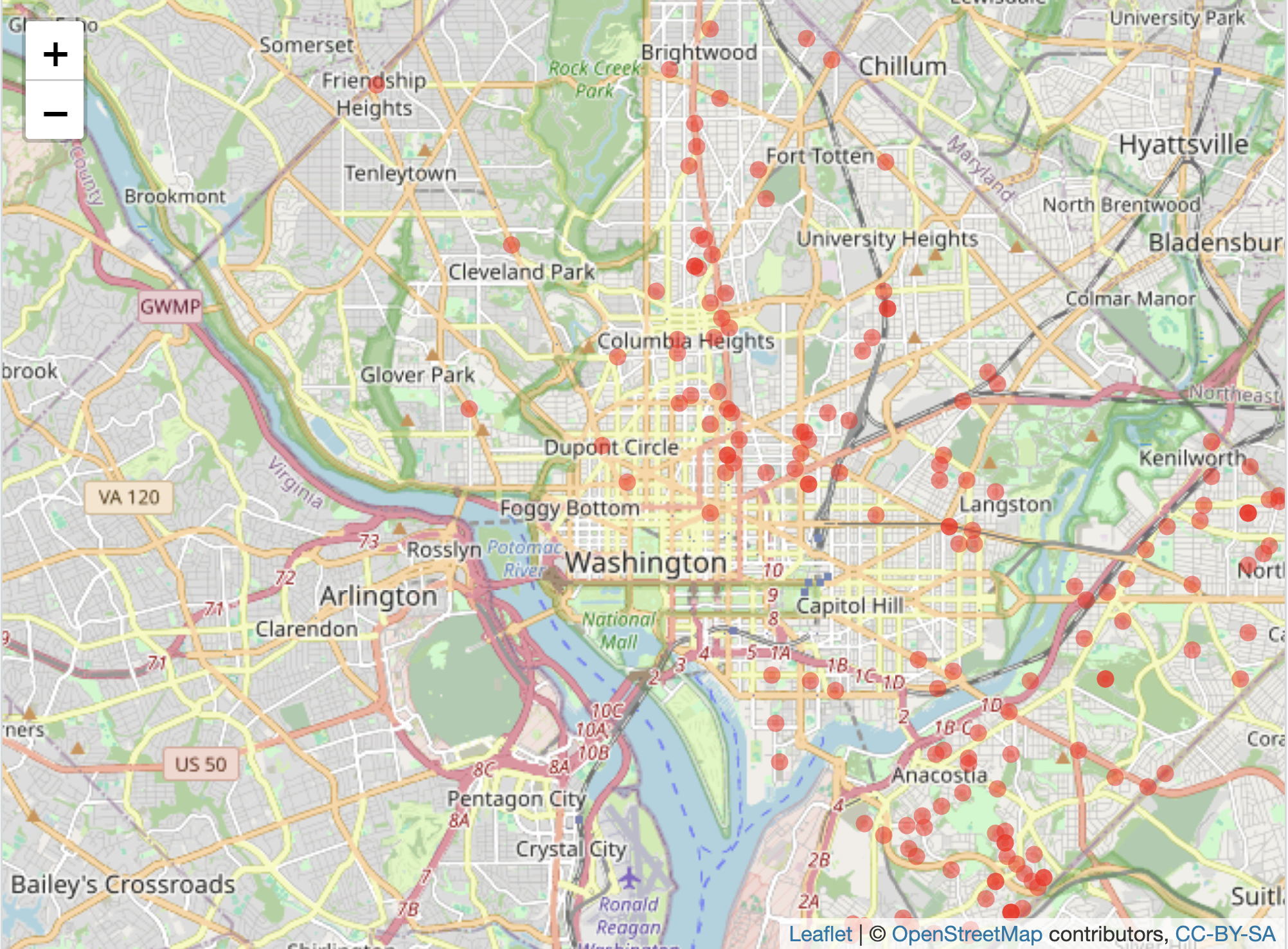
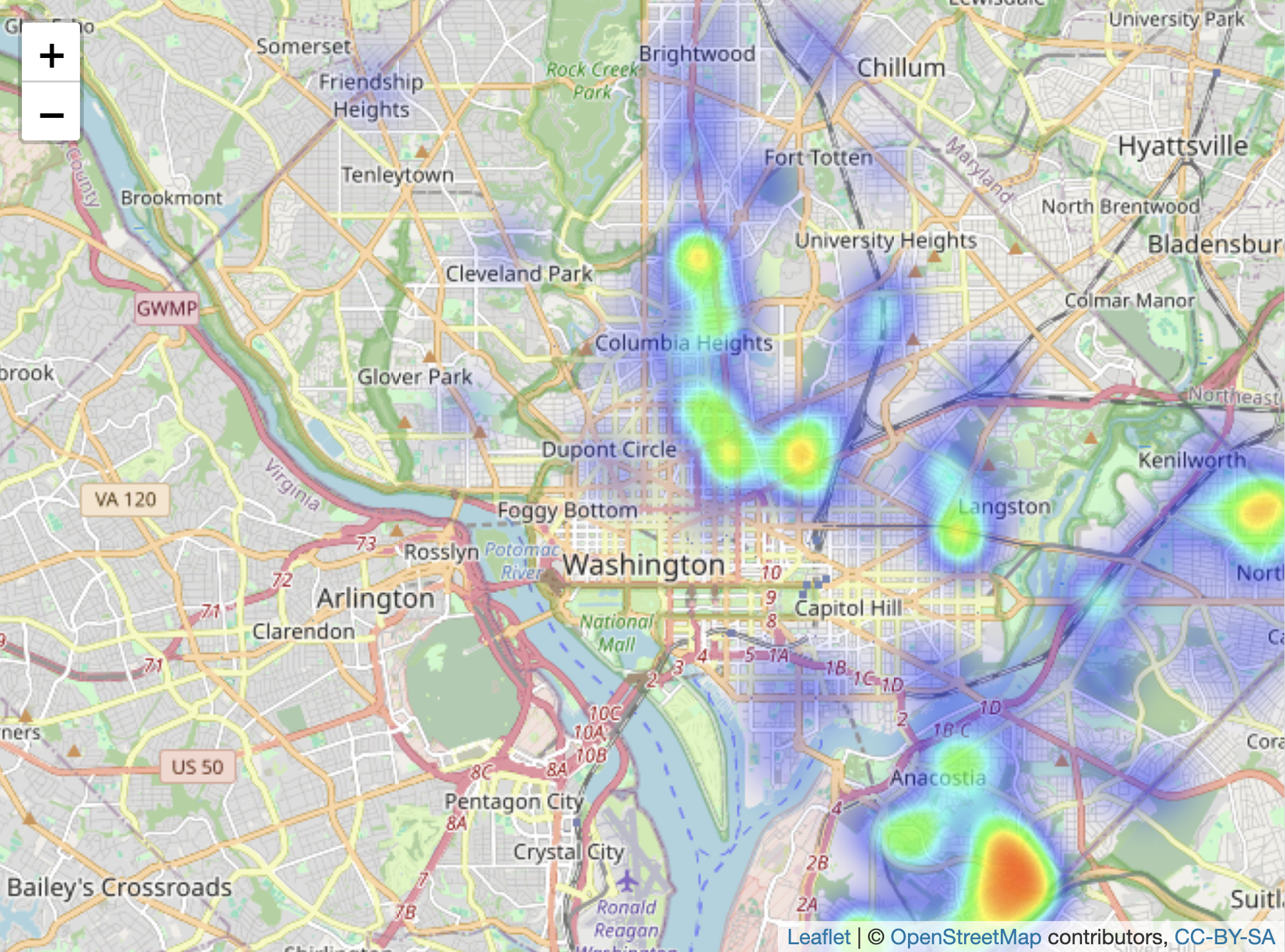
FIGURE 6.6: Interactive map of Washington, DC, displaying homicides in 2024, with OpenStreetMap as the base layer. The upper panel shows individual homicide locations as points, while the lower panel presents a heatmap of homicide concentrations.
These maps in leaflet are meant to be interactive, rather than printed through an RMarkdown file as an image to a Word or PDF document. Creating these images requires the creation of maps as plotted graphics.
Creating static polygon and point maps
Static maps based on shapes or points imported from a ShapeFile or .geojson file require the sf package, but the inclusion of a base layer necessitates ggspatial, along with functions from the tidyverse for data wrangling and visualization, and optionally labelling with ggrepel.
The same .geojson file of administrative boundaries, read into R with st_read() and saved as sa_admin_boundaries can be plotted in a static ggplot2 graphic. The geometry in the ggplot() graphic, geom_sf(), plots any “simple features” map object (such as a ShapeFile or geoJSON file) imported into R with st_read(). The function will automatically find the geometry column (in data=sa_admin_boundaries) for plotting. Note that drawing static maps via ggplot() takes a little more computing time than the interactive maps; so after you enter the commands below, you may have to wait a minute or so to see the next prompt >, and then perhaps 1-2 minutes for the actual map to appear in the “Plots” pane.
The simplest plot of the administrative boundaries would consist of two lines ggplot() + geom_sf(data=sa_admin_boundaries). For completeness, however, static maps of this kind usually include an orientation symbol and a scale legend. Among other functions, the ggspatial package provides these features. The two components are added with the functions annotation_north_arrow() and annotation_scale(). The function includes a style= north_arrow_fancy_orienteering for a particular orientation style, placing it at the bottom right of the graph (location= "br"). The intended width of the legend scale on the plot area is controlled with width_hint= as a proportion of 1.
To plot both the boundary lines for wards and the air pollution level, we specify a fill layer within the aesthetic aes() function. The geom_sf() function still requires that the dataset data= is explicitly identified. Figure 6.7 shows the administrative wards filled by average level of air pollution.
ggplot() +
geom_sf(aes(fill=air_pollution_level), data=sa_admin_boundaries) +
theme(legend.position = "bottom") +
annotation_north_arrow(location = "br",
style = north_arrow_fancy_orienteering) +
annotation_scale(location = "br", width_hint = 0.4) +
scale_x_continuous(breaks = seq(18, 19, by = .5))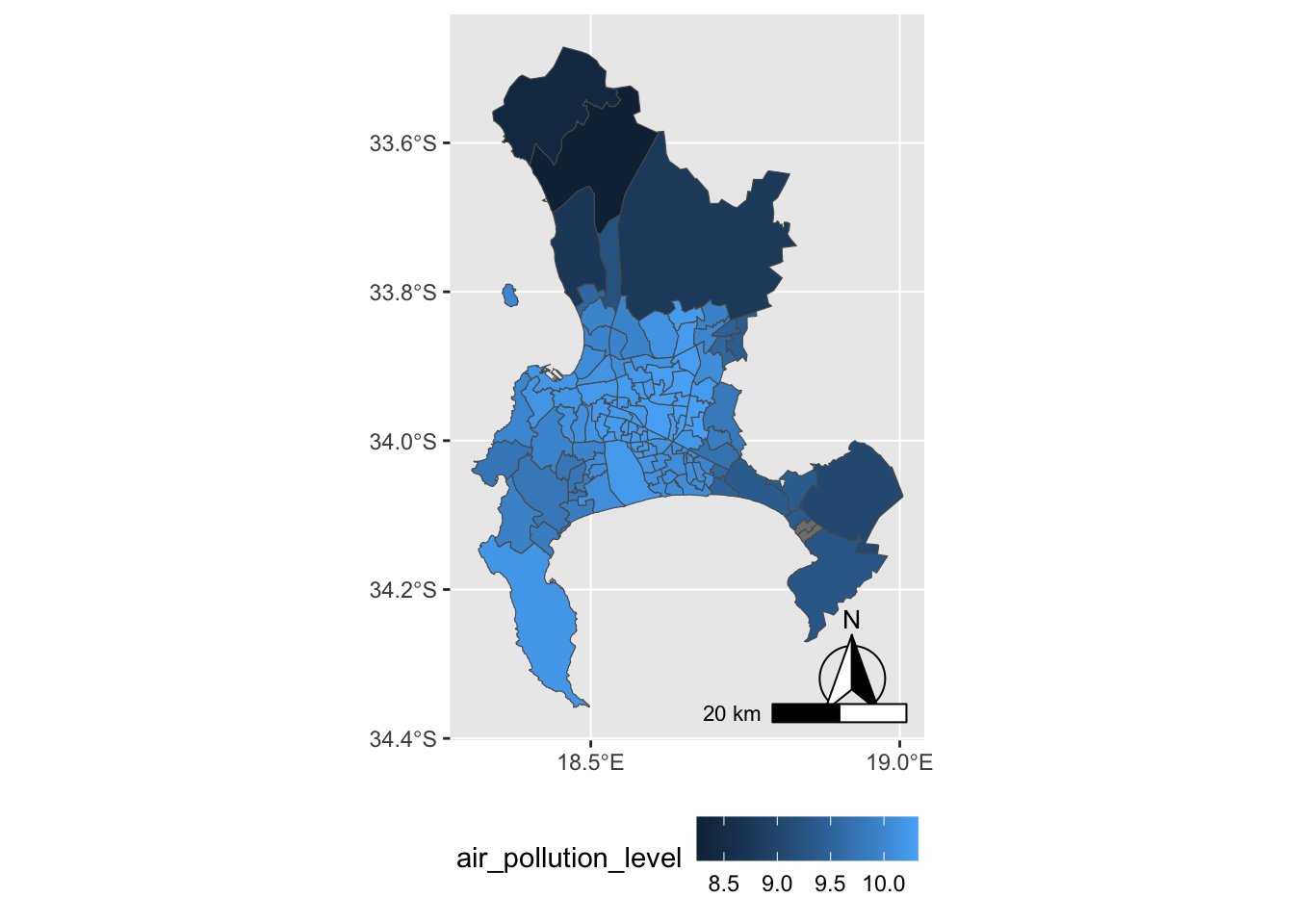
FIGURE 6.7: Heat map of Cape Town, South Africa, showing average PM2.5 air pollution concentration by administrative unit in 2011, visualized with . Shading represents pollution levels, with darker areas indicating higher concentrations.
Perhaps the most common use of maps is in organizing election results by county.
6.3 Mapping elections in red, blue, and purple
The creation of ‘choroplethic’ heatmaps for elections — such as the red-blue USA election maps in every presidential election — relies upon the same principles of map-making we have seen in drawing a map of administrative wards in Cape Town. For example, in elections, the geographic unit (such as a State, County, or precinct) is shaded either by a categorical variable (win/loss for a candidate) or continuous variable (a candidate’s margin of victory).
To illustrate how to create election maps, we approach it first with the same geom_sf() function in the ggspatial package. Second we will consider the limitations of these maps in the construction of “cartogram”-style maps with the help of the cartogram package (Jeworutzki 2023). Finally we will review how interactive maps can be created to investigate gerrymandering.
The basic steps to create these maps are as follows:
- Decide upon a geography for the map – Counties? States? precincts?
- Find a boundary line file that outlines the geography.
- Find the election results – aggregated to the intended geography; prepare a data table.
- Merge the election results with the map file, on the key field that links the map geographies together.
- Display the resulting map + election results.
A map of Michigan counties
Our goal is to map the outcome and margins of victory for presidential candidates Trump and Clinton in the 2016 election, at the Michigan County level. The first step is to identify a suitable boundary line file. Many units of government have geographic data portals with open access geospatial data. A simple internet search will find these portals. Within each one, boundary lines files can easily be downloaded for analysis.
The Michigan County boundary line file is Counties__v17a.shp. From a working directory, use the sf package to read in file, with st_read():
## Reading layer `Counties__v17a' from data source
## `/Users/kilburnw/Documents/Counties__v17a.shp'
## using driver `ESRI Shapefile'
## Simple feature collection with 83 features and 15 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: 161300 ymin: 128100 xmax: 792200 ymax: 859200
## Projected CRS: NAD83 / Michigan Oblique MercatorThe geospatial dataset consists of 83 rows (one for each Michigan county) and 15 variables describing each row. Like the geoJSON file for Cape Town, the geometry is MULTIPOLYGON referencing the shapes for each Michigan county. Enter glimpse(michigan) to observe different features of the dataset, in particular NAME and LABEL that describe the counties, the first row of which are for Alcona and Alcona County. In addition to name, the counties are identified by numeric FIPS codes, from States down to the smallest Census Bureau tracts. Both columns contain the same information, the only difference being the leading zeros. (States are identified by a two-digit code that precedes the FIPS code shown here; for example, Michigan’s State level FIPS code is 26, thus the FIPS code identifying Alcona County as a county in Michigan would be 26001).
Before moving on to the next step, we will plot the michigan simple feature dataset:
FIGURE 6.8: Map of Michigan county boundaries created with to plot spatial data.
As expected, Figure 6.8 shows the outlines of the Michigan counties from the simple features data michigan. The next step is to link election results to the counties, by merging an election dataframe to the michigan counties map data. The election data, michigan12_16.csv, contains County-level presidential vote counts for 2012 and 2016. It is organized with Counties on rows and votes, along with various other county characteristics on the columns.
Using the read_csv() we will read in the CSV file and store it as MI1216.
Like the michigan map data, the MI1216 dataset contains 83 rows, one for each Michigan county. There are two variables that record the name of each county, as well as a FIPS code column. To merge the two datasets, one method would be to use a join, such asinner_join(). The two matching key variables from each dataset are FIPSNUM in michigan and fips in MI1216. michigan<-michigan %>% inner_join(MI1216, by=c("FIPSNUM", "fips")
Because the order of the rows in each dataset matches each other, an alternative to a join is simply to bind the columns from one dataset to the other, with the cbind() function. Since the datasets mirror each other in row structure — Michigan counties in rows in the same alphabetical order — we can simply merge the MI1216 data onto it adding all the columns from MI1216 to the side of michigan. This is easy to do with the function cbind().
The dataset michigan now contains the geographic data as well as the attribute elections data. To verify, try glimpse(michigan).
A choroplethic map of county-level election results
First we will plot a choropleth map of Michigan with some 2016 election results. We will plot the map with ggplot() and code counties the traditional red-blue colors. Then in a second map, we will fill counties by a color gradient including purple to identify the ‘swing’ counties. So now we can fill in the map with colors from the 2016 election, assigning blue to counties where Clinton won, and red to counties where Trump won.
We need to specify for the map which counties each candidate won. One way to do this would be to specify an indicator column that takes the values 1 if Clinton won and 0 if Trump won. We will add this measure to the dataset with the ifelse() function. The function will evaluate a condition for each row of the dataset, whether clinton_vote is greater than trump_vote: clinton_vote > trump_vote. Then counties where the condition is true will receive a score of 1 and 0 if false.
We could leave this indicator as is, with 0 and 1 for Trump and Clinton — but we could also associate candidate names with these numbers. Doing so requires us to convert the numeric scores into another variable type, a factor variable, which combines a numeric score with an associated verbal label, such as “Trump” and “Clinton” in this case. To convert it, we use mutate() with an additional function, as_factor() that will convert the numeric score into a factor measure. All we have to do is specify the verbal labels for each numeric code, after converting it to a factor with as_factor():
michigan<- michigan %>%
mutate(indicator = as_factor(indicator))
michigan<- michigan %>%
mutate(indicator = fct_recode(indicator,
"Trump" = "0", "Clinton" = "1"))To create an election map that simply displays a red-colored county for Trump and blue for Clinton, we need to add a fill color. That fill will be determined by the indicator variable, and the color we set manually with scale_fill_manual(). To add the fill, we specify it as geom_sf(aes(fill=indicator)). Since the indicator variable has only two levels, “Trump” and “Clinton”, we will specify two colors in the order red and blue, and then add a name for the legend: scale_fill_manual(values = c("red", "blue"), name= "Winning candidate").
A simple red-blue election map could be visualized with the following lines of code:
ggplot(data=michigan) +
geom_sf(aes(fill=indicator)) +
labs(title="Michigan County level vote",
subtitle="2016 presidential election") +
scale_fill_manual(values = c("red", "blue"),
name= "popular vote winner")The map for this code would include X and Y axes scale labels with the latitude and longitude coordinates. To remove the coordinates, add theme_void(), and then reposition the legend to the bottom of the map, theme(legend.position = "bottom"), so that there is less white space above and below it. Figure 6.9 illustrates this adjusted map of the 2016 County level results. Note that in the grayscale, text printed version of the map, the “blue” Counties appear darker than red.
ggplot(data=michigan) +
geom_sf(aes(fill=indicator)) +
labs(title="Michigan Counties, 2016 presidential election") +
scale_fill_manual(values = c("red", "blue"),
name= "popular vote winner")+
theme_void() +
theme(legend.position = "bottom")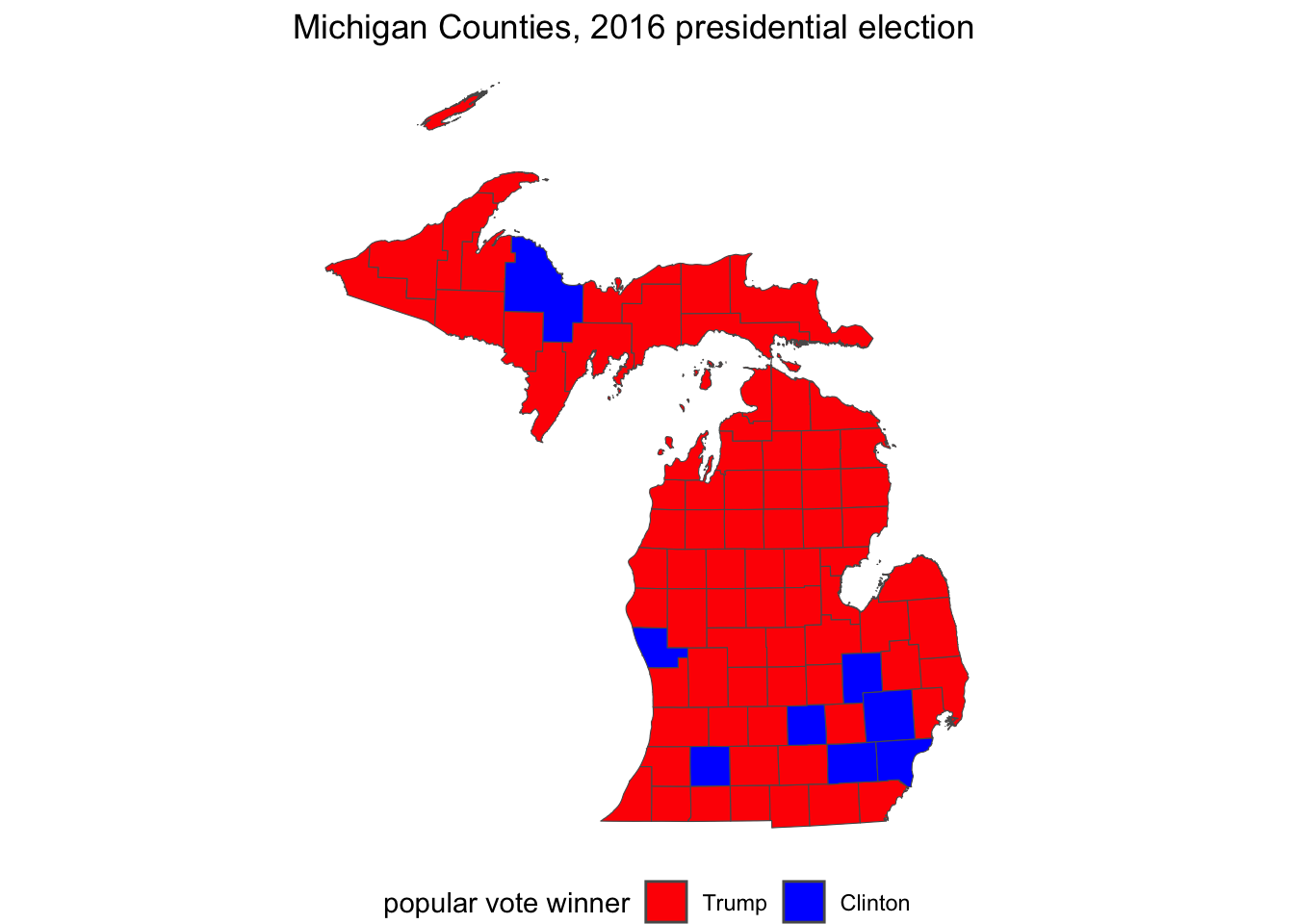
FIGURE 6.9: Traditional red-blue election map of Michigan counties visualized with . On the grayscale printed version of the map, blue counties appear darker than red.
Blending counties: red, blue, and purple
Of course, a common criticism of maps such as these is that the map obscures the votes received by the loser in each county. After all, Trump’s margin of victory was less than 10,000 votes, so we could create a map displaying the shift between red and blue — to purple — among the counties that were relatively close. The key to understanding how this map would be constructed is to imagine that within each state we are plotting the size of the margin of victory won by either Trump or Clinton along a color spectrum ranging from red — through purple — to blue.
Instead of specifying red and blue colors with scale_fill_manual(), we will use a function that creates a gradient of colors between the two. This function is scale_fill_gradient2(), where the 2 stands for a divergent contrast between the two colors. By default, the function uses the color white as the midpoint, so instead we will specify purple as the midpoint in the transition.
The next decision is whether to plot Trump’s percentage minus Clinton’s, or vice versa. That choice affects which color is at the minimum of the gradient and which is specified at the maximum. If it is Trump’s percent of the vote minus Clinton’s, then the minimum, or low would be blue and the high red: larger values of this measure would correspond to a more red state, while lower would be blue, and then purple is the midpoint: scale_fill_gradient2(low="red", mid="purple", high="blue").
We create the margin of victory measure:
And then create the map displayed in Figure 6.10:
ggplot(data=michigan) +
geom_sf(aes(fill=margin)) +
labs(title="Michigan Counties, 2016 presidential election",
subtitle="percentage margin of victory by Trump (red)
or Clinton (blue)") +
scale_fill_gradient2(low="blue", mid="purple", high="red") +
theme_void() +
theme(legend.position = "bottom")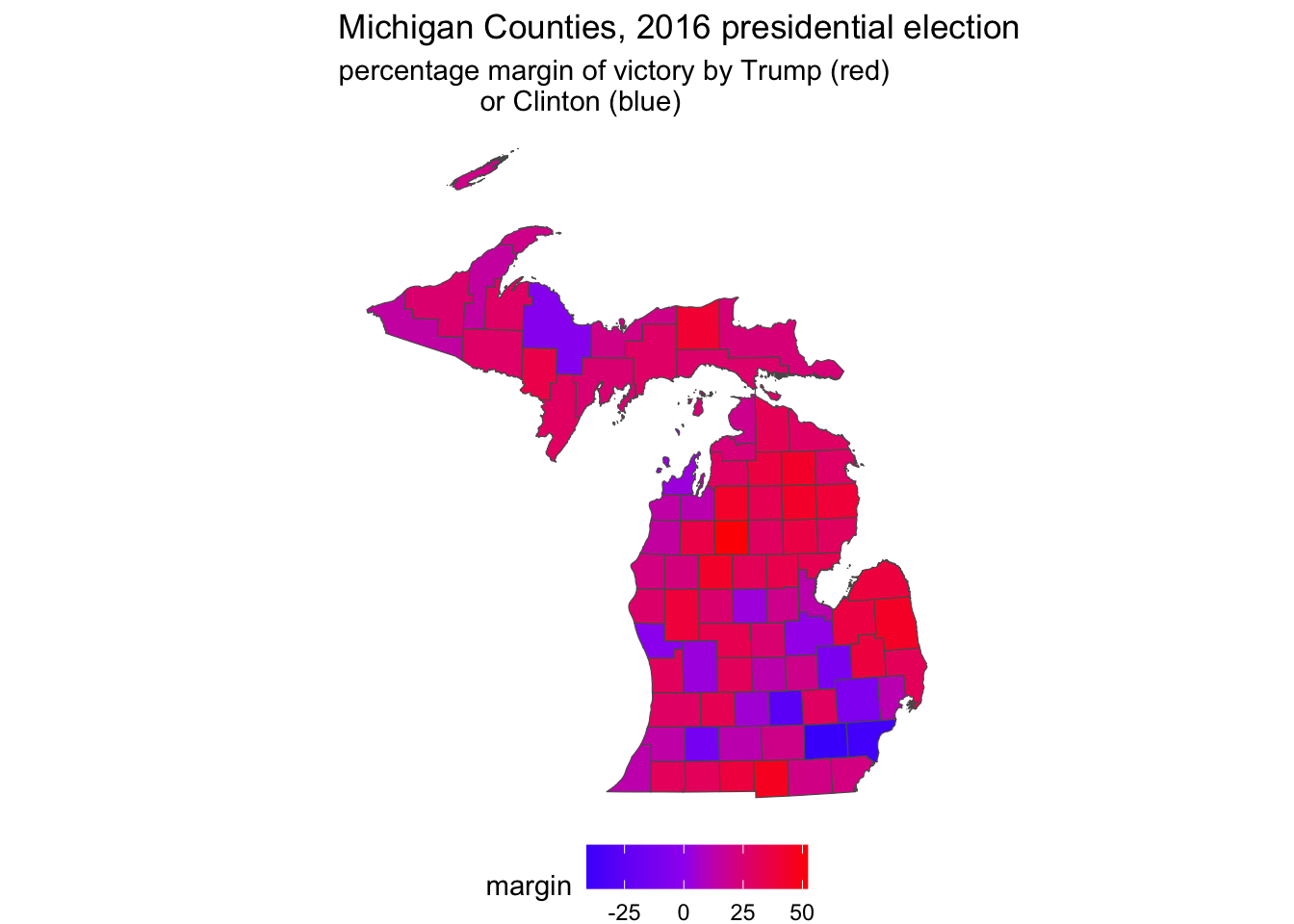
FIGURE 6.10: County level election map displaying a percentage margin of victory from red through purple to blue, visualized with . On a graycale printed page, these color transitions are not visible.
Notice in the legend that ggplot automatically chooses the breakpoints, the range of percentage scores associated with a particular color. In this case, it chose four bins, or ranges, in increments of 25 percentage points. We can specify our own preferred breakpoints; perhaps in units of ten, breaks=c(-30, -20, -10, 0, 10, 20, 30). This argument would be added to scale_fill_gradient2() after high="red". Another aesthetic change would be to move the legend to the side, under the upper peninsula, theme(legend.position = "left"). Other maps show these with a neutral color such as white as the midpoint, so that the map emphasizes red or blue shades. Figure 6.11 displays such a map:
ggplot(data=michigan) +
geom_sf(aes(fill=margin)) +
labs(title="Michigan Counties, 2016 presidential election",
subtitle="percentage margin of victory by
Trump (red) to Clinton (blue)") +
scale_fill_gradient2(low="blue", mid="white", high="red",
breaks=c(-30, -20, -10, 0, 10, 20, 30)) +
theme_void() +
theme(legend.position = "left")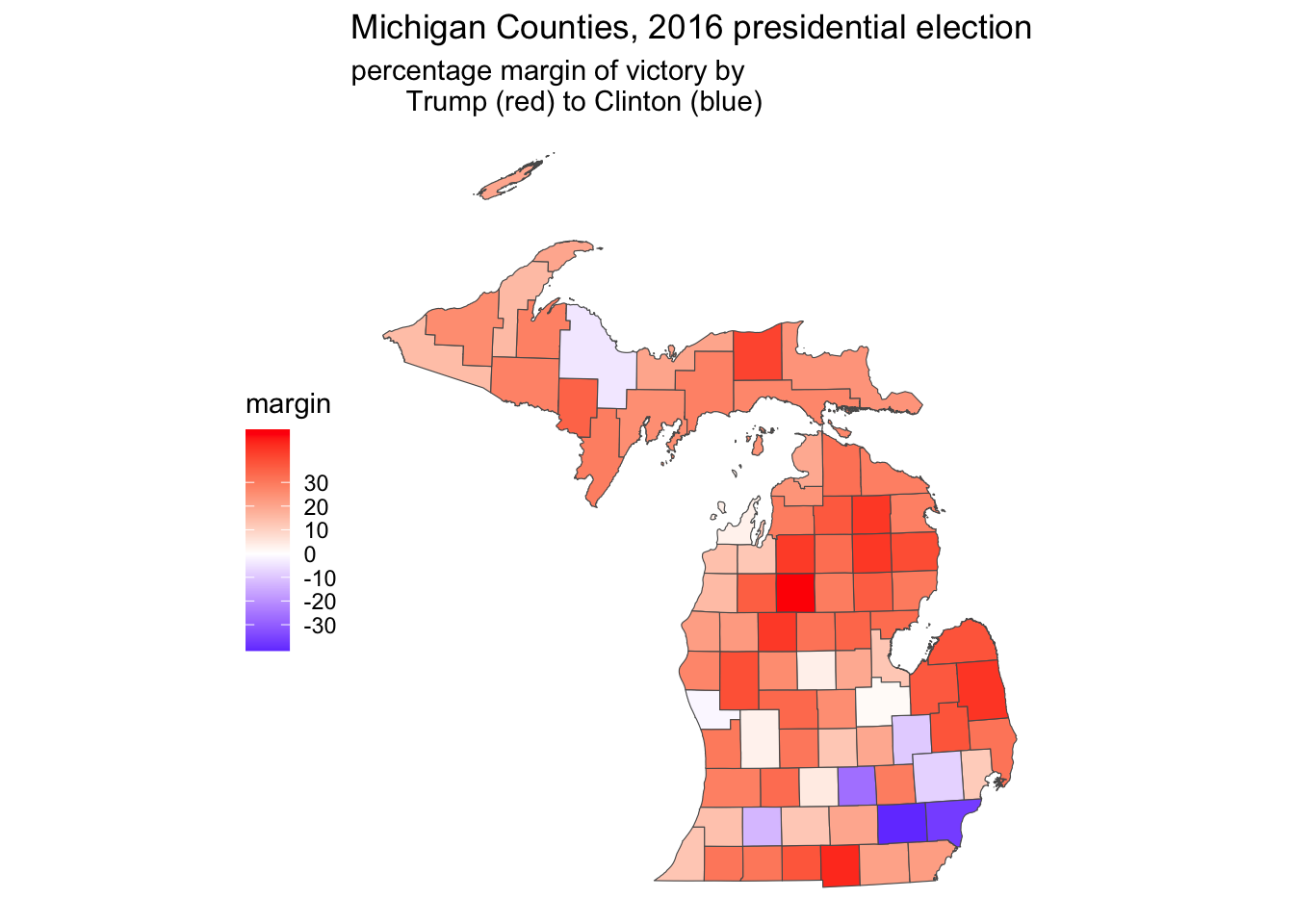
FIGURE 6.11: County level election map displaying a percentage margin of victory from red through white to blue, in increments of ten, visualized with . On a graycale printed page, these color transitions are not visible.
For an introduction to other mapping packages, see Machlis (2019).
6.4 Cartogram corrections to election maps
A cartogram is a type of map in which the area of a geographic unit as it appears on the map is intentionally distorted by another feature of the geographic units, such as population. In the case of a Michigan County election map, this transformation ensures that counties with relatively lower populations (or votes cast) appear proportionally smaller. By scaling geographic areas in this way, cartograms prevent the common misconception that larger land areas correspond to larger contributions to the total vote, a bias inherent in traditional maps. In R, the cartogram package (Jeworutzki 2023) will transform existing election maps into the cartogram style visualization. We will transform the Michigan County red-blue election map. Install the package cartogram if you have not already install.packages("cartogram"), and attach it.
Cartogram of the Michigan county presidential vote in 2016
The starting point for the cartogram is an existing map constructed via the sf package. In cartogram, starting with a map object the main function for creating the cartogram map is cartogram_cont(). The necessary arguments are the map object, the variable for scaling the geographic boundaries, and a maximum number of iterations for the algorithm to run in order to create the new boundary lines. In this example the cartogram uses the same michigan simple features data object used to construct the election heat maps with ggplot2().
The cartogram will be used to draw County shapes in proportion to their total vote — how much each County contributed to the total vote statewide. So the County shapes for lower population counties will be drawn smaller, higher counties larger, and the color of each County will be red or blue accordingly. The choropleth map shows that upper Michigan is relatively red, along with the thumb, but most of these counties are relatively sparsely populated. So the cartogram algorithm redraws the County lines, making these counties smaller and more populous counties larger.
One potential obstacle in drawing the cartogram is that the algorithm that scales boundary lines requires an acceptable map projection as the starting point for finding the geographical ‘center’ of each geographic unit. The st_transform() function for altering the projection may be necessary if the cartogram function returns an error indicating a different projection must be used.18
To begin we specify the projection:
Through st_transform(), we specified the CRS as epsg:3857 and assigned it to the input map michigan. Next we will draw a cartogram map, with the function cartogram_cont(). We specify the output (mi_cart), the input map (michigan), and the measure with which to draw the cartogram (total_votes). The cartogram algorithm works iteratively, trying to find an arrangement of the area marked by county lines that satisfies the condition of drawing the county lines relative to total_votes, counties with more votes to contribute to the total are drawn relatively larger, and smaller vote counties are drawn with a smaller geographic area. It finds one solution, then tries to improve upon it. Setting itermax= determines how many of these iterations to go through; four is fine. Changes beyond that tend to be subtle.
The cartogram algorithm returns back a dataset like michigan in every respect except the county line coordinates, which are now scaled according to the cartogram_cont() algorithm. The new cartogram map is stored as mi_cart. We will redraw the election map with ggplot() and geom_sf(), essentially repeating the same ggplot() syntax from Figure 6.9 applied to mi_cart as the input data rather than michigan. (To draw a cartogram style map of Figures 6.10 or 6.11, we would rely on the syntax for each of those maps.)
Figure 6.12 displays the cartogram representation of Figure 6.9, Michigan County level votes in the 2016 presidential election. Compare the Cartogram to the prior election map to observe the differences. TK In the cartogram, the upper and interior solidly ‘red’ parts of the State are drawn much smaller, while the more populous counties surrounding and containing Detroit on the southeast side of the State are drawn proportionally larger. Trump won the State’s popular vote in part by running more competitively in these counties, which appear purple in the color gradient map; perhaps a cartogram map of margin of victory would explain the election result better than the red-blue version.
ggplot(data=mi_cart) +
geom_sf(aes(fill=indicator)) +
labs(title="Michigan Counties, 2016 presidential election") +
scale_fill_manual(values = c("red", "blue"),
name= "popular vote winner")+
theme_void() +
theme(legend.position = "bottom")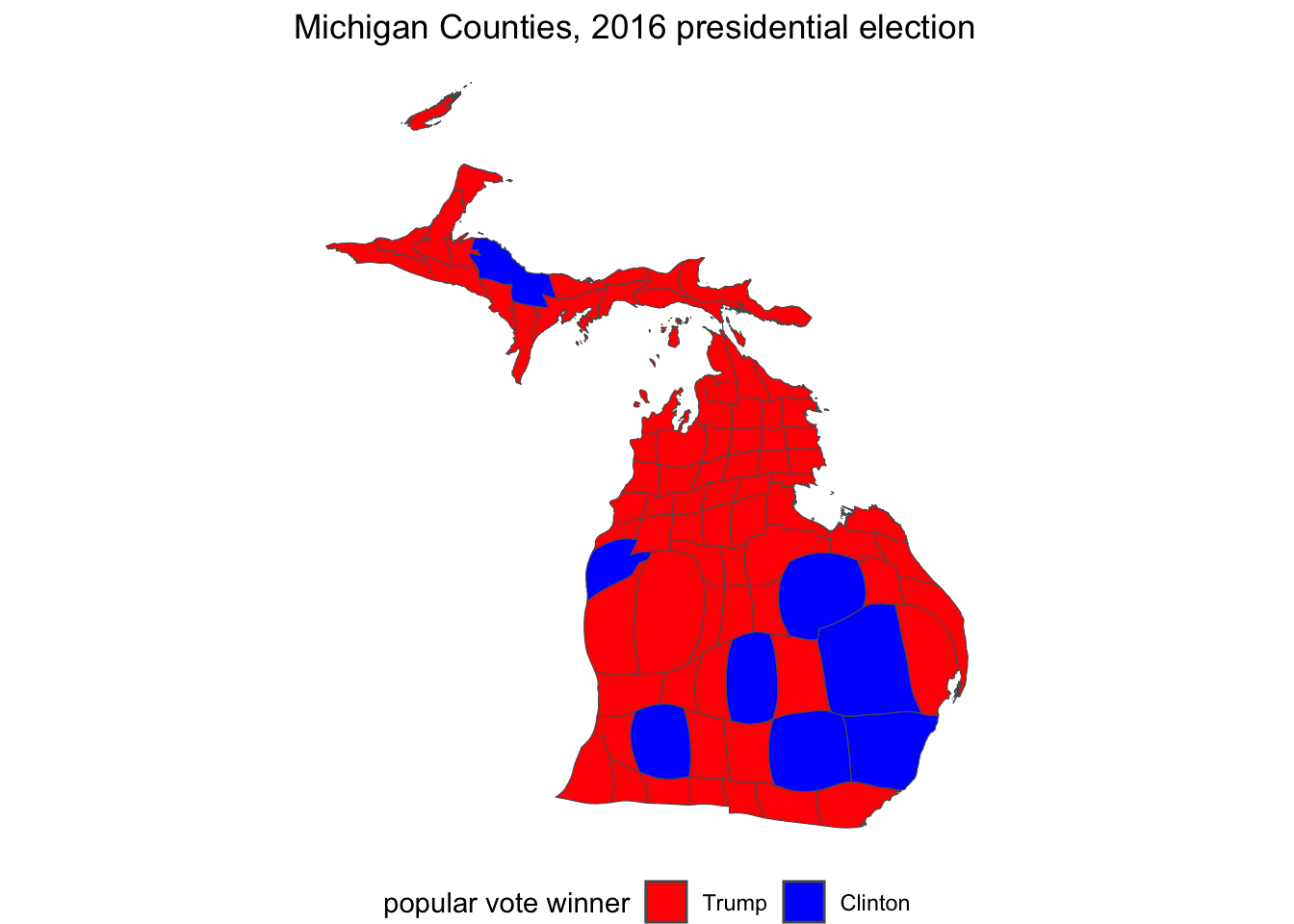
FIGURE 6.12: Cartogram representation of the 2016 presidential vote in Michigan Counties, visualized with the package.
6.5 Measuring gerrymandering in legislative districts
The term ‘gerrymandering’ refers to the practice of drawing odd or unusually shaped legislative districts, typically for the purpose of partisan advantage. The study of gerrymandering has a lengthy history in political science; for an overview see McGhee (2020). Two common ways of assessing gerrymandering is through the analysis of a legislative district shape, the degree of compactness, and the skew or lopsidedness of the vote. These gerrymandering metrics can be assessed with some extensions to the spatial operations we have already learned and some skills in data wrangling. This section assumes the sf and leaflet packages are already installed, and that the tidyverse packages are previously attached.
In this example, we will assess legislative district shape, compactness, for the 2011 redistricting plan for the Michigan State Senate. Like any other .geojson file, we read the file with st_read() from the sf package.
In addition to identifying information about the legislator within each district, the mi_senate_2011 file contains border lines of districts in the geometry column. Like previous map files reviewed in this chapter, leaflet will automatically read the geometry column and locate the map boundaries, centering the boundaries in the map Viewer. Because the boundaries are polygons, we add the boundary map with the function addPolygons():
The map will appear as in Figure 6.13, within the Viewer pane, displaying the outline of the districts.
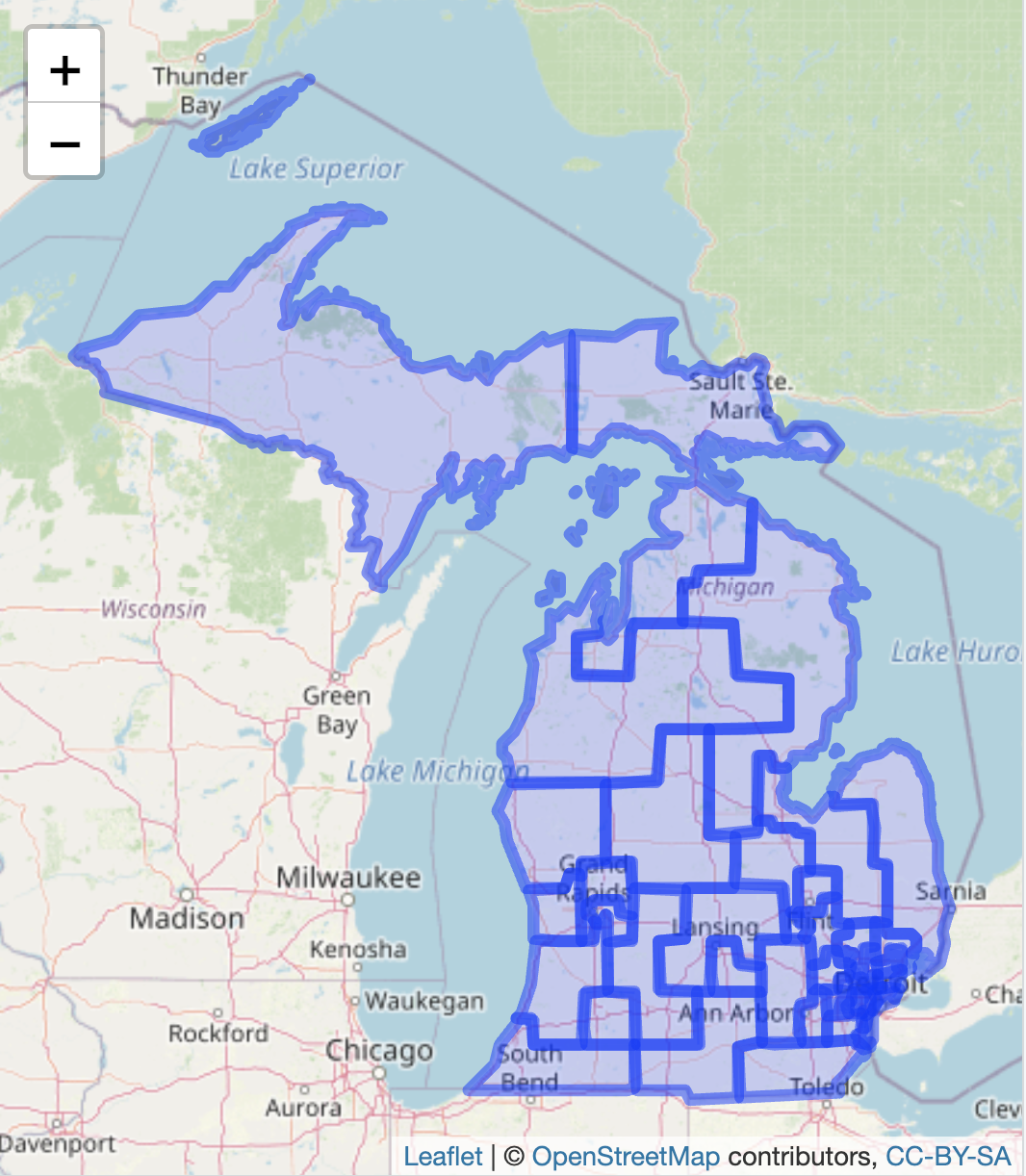
FIGURE 6.13: Interactive map of the 2011 Michigan Senate districts, with OpenStreetMap tiles as the base layer.
To further explore the map, features from the map data can be added as a popup label, by adding the popup= argument to addPolygons(). For example, to display the legislator name contained within the dataset LEGISLATOR column, the function would appear as addPolygons(data=mi_senate_2011, popup=~LEGISLATOR). There are multiple columns in the dataset that describe the districts: “PARTY” and “NAME”. The paste() function combines the two fields; the map display supports HTML tags for formatting the popup menu items. We could create a new column in the mi_senate_2011 dataset:
mi_senate_2011<-mi_senate_2011 %>%
mutate(popup_content = paste("<strong>Name:</strong> ", NAME,
"<br><strong>Legislator:</strong> ", LEGISLATOR,
"<br><strong>Party:</strong> ", PARTY))The tags enclose the text. For example, <strong> and </strong> enclose Name and present the text in boldface. The tag <br> places a line break before the text, such as before “Legislator”. Then we can plot the map with more descriptive information contained in the popup menu:
The map of the districts will be redrawn, and clicking on any one of the districts will reveal the popup containing information about the three legislative districts. Try creating the popup_content and redraw the map with the popup= argument and observe the behavior of the map information.
We will calculate some gerrymandering metrics based on assessing compactness. The idea of compactness measurement is that a district shape is compared against a hypothetical compact shape, such as a circle, square or polygon. One of the most common compactness measures is the “Convex Hull”, a comparison of the shape of the district to a polygon that encloses the district. To illustrate, we start with the 29th district, which encompasses the city of Grand Rapids and areas east and southeast.
To ease visualization of the compactness measure, we will filter on this district from the data and save it as a single district datafile, district_29:
Try visualizing the district with leaflet() %>% addPolygons(data=district_29, popup=~popup_content) %>% addTiles().
Convex Hull score
From the sf package we use the function st_convex_hull() to create the convex hull around the district:
The function searches inside district_29 for a column labelled geometry, drawing a minimally encompassing polygon around the district. The convex hull appears around the district as the dashed line in Figure 6.14. Two layers of addPolygons() draw the district and the convex hull.
leaflet() %>%
addPolygons(data=district_29, popup=~popup_content) %>%
addPolygons(data = district_29$convex_hull, color = "red", weight = 2,
dashArray = "5, 5",
fillOpacity = 0.3, fillColor = "red") %>%
addTiles()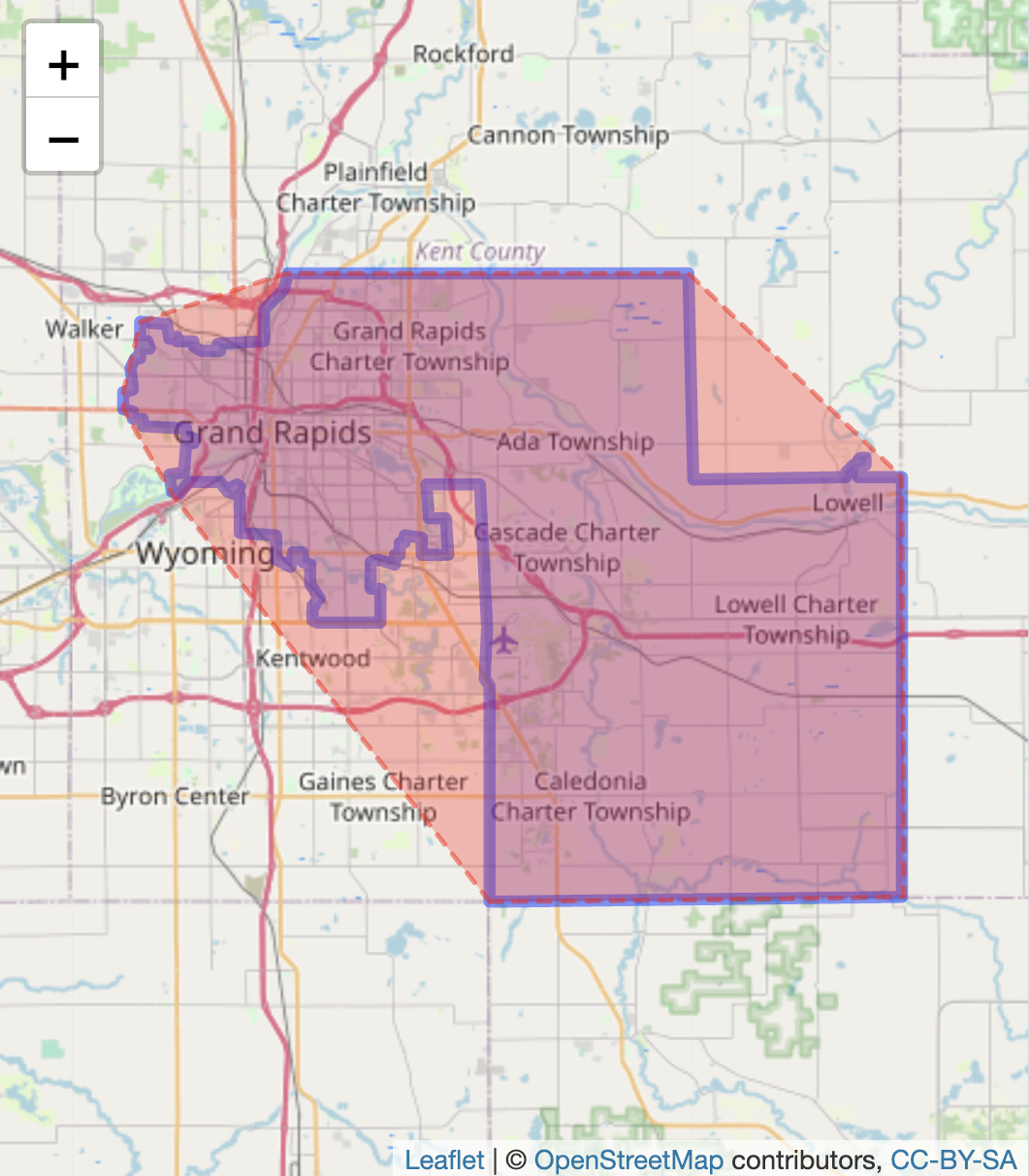
FIGURE 6.14: Interactive map of Michigan’s 29th Senate district (2011 plan), with OpenStreetMap tiles as the base layer. The district boundary is outlined with a convex hull surrounding it.
The convex hull metric is simply the ratio of the district area to the area of the hypothetical convex hull enclosing it. The closer the ratio is to 1, the more compact the district. The function st_area() will calculate the area of both the district and the convex hull.
The st_area() function automatically searches for a “geometry”column. For calculating convex_hull_area, since the convex_hull column is labelled convex_hull it is specified as part of the district_29 dataset. The default scale from the st_area() function is square meters; the stored units and area in boundary_area are a little over 600 million squared meters.
## 631850157 [m^2]Converting the squared meters to squared kilometers (dividing by one million: 1000 \(x\) 1000 for squared meters) results in an estimate from st_area() of 631.85 squared kilometers. Notice in the data file district_29 the recorded area in the column SQKM is 632.5. The convex hull measure is
## 0.7894 [1]The result, .789, would be interpreted as the legislative district area being 79 percent of the convex hull. Based on this measure, the district is relatively compact, although any district’s compactness must be interpreted in the context of the redistricting plan and other districts. Studies of the compactness of a redistricting plan take account of multiple measures.
Polsby-Popper score
In the Polsby-Popper measure the hypothetical compact reference shape is a cirle. The score compares the area of the district to the area of a circle (surrounding the district) defined by a circumference equal to the district perimeter (Polsby and Popper 1991). The more the district resembles a circle, the more compact and the closer the score will be to 1. A district shape that is less circular, irregular and elongated would have a lower Polsby-Popper score.
The formula comparing the area of the district to the area of the circle is \(A_d / A_c\). To avoid actually calculating the area of such a circle, the formula is expressed in values measured from the legislative district as substitutes for the circle. We will compare the result from this formula with an estimate of the circle area from st_area().
Polsby-Popper compactness =\(\frac{4\pi A_d}{P_d^2}\)
where \(A_d\) is the area of the district, and \(P_d\) is the perimeter of the district. In the formula, the ratio of \(\frac{A_d}{P_d^2}\) is multiplied by 4 times pi, \(\pi\).
Taking a closer look at the formula, recall that the perimeter of a circle is (\(2 \pi r\)). In the Polsby-Popper metric, we know the perimeter of the circle (equal to the perimeter of the district), but we do not know the radius of this circle. We need to find the area of the circle with the knowledge of what the perimeter should be. The radius \(r\) can be expressed in terms of the perimeter \(P\), \(r=\frac{P}{2 \pi}\). The area of a circle is \(\pi r^2\). We can substitute this perimeter value into the formula for the radius, resulting in area\(=\pi (\frac{P}{2 \pi})^2\). Applying the exponent 2 reduces down to the area of the circle = \(A=\frac{P^2}{4 \pi}\). The compactness measure is the area of the district divided by the area of the circle with the same circumference as the district perimeter, or \(\frac{A_d}{\frac{P^2}{4 \pi}}\). The \(4\pi\) moves up to the numerator, resulting in the Polsby-Popper formula.
To estimate the Polsby-Popper score, we rely on st_area() to find the area of the district. Next we find the perimeter by tracing the length around the boundary of the district, with st_boundary() nested within st_length().
district_29 <- district_29 %>%
mutate(boundary_area = st_area(district_29)) %>%
mutate(boundary_perimeter = st_length(st_boundary(district_29)))We previously calculated boundary_area with the st_area() function. The perimeter is stored as column boundary_perimeter in the district_29 dataset. To visualize the circle defined by the district perimeter compared to the district, we draw an enclosing circle around the district — the circle with a circumference equal to the perimeter of the district, centering the circle over the district. This ‘centering’ is accomplished by locating the geographic centroid (or center point) of the district and drawing a circle with an appropriate radius from that centroid, for the circumference equal to the district perimeter. For the visualization, we calculate the radius based on the formula for the circumference: \(C = 2 \pi r\).
Next to find the centroid of the district, we use the function st_centroid():
To see where the centroid is located, in the lines of leaflet() code, try inserting the line addMarkers(data=district_29centroid) %>% in front of the last line addTiles(), in the previous set of commands to visualize the district in the Viewer pane. Now that the radius and centroid are calculated, the circle can be drawn around the district:
The circle centered over the district appears as in Figure 6.15:
leaflet() %>%
addPolygons(data=district_29, popup=~popup_content) %>%
addPolygons(data=district_29$circle, color = "red", weight = 2,
dashArray = "5, 5",
fillOpacity = 0.3, fillColor = "red") %>%
addTiles()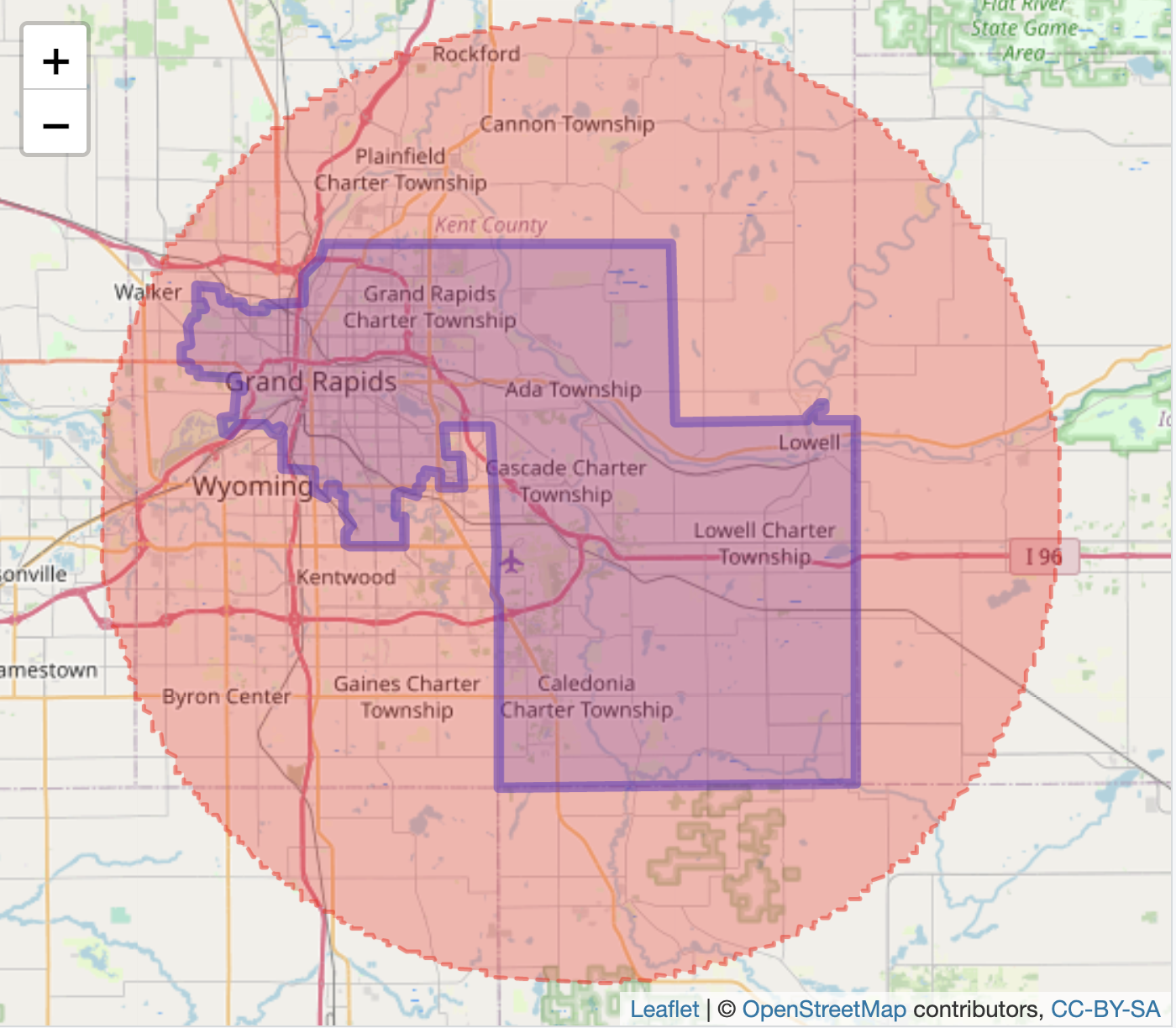
FIGURE 6.15: Interactive map of Michigan’s 29th Senate district (2011 plan), with OpenStreetMap tiles as the base layer. The district boundary is outlined with the Polsby-Popper circle surrounding it.
The circle does not appear perfectly smooth around the perimeter — it has jagged lines resulting from the ‘buffer’ algorithm. We will compare the buffer calculation to the perimeter-based calculation. In R the name pi is reserved for \(\pi\):
## 0.3102 [1]The result, 0.3102, means the area of the district is 31 percent of the area of the circle. Next we approximate this calculation with the buffer area of the circle. We already have the area of the district. The denominator of the measure is the area of the circle calculated from st_area():
## 0.3067 [1]The approximation from the buffer circle is .3067, fairly close to the calculation based on the formula.
Compactness calculations across a redistricting plan
Researchers assess compactness across each district within a redistricting plan. Given a map of districts, we can do so by grouping the calculations by district:
mi_senate_2011 <- mi_senate_2011 %>%
group_by(NAME) %>%
mutate(convex_hull = st_convex_hull(geometry)) %>%
mutate(convex_hull_area =st_area(convex_hull)) %>%
mutate(boundary_area = st_area(geometry)) %>%
mutate(hull_score = boundary_area / convex_hull_area) The mutate() function creates the new variables and mi_senate_2011 now contains a set of the scores, hull_score, for each district. We can list the scores below:
## Simple feature collection with 38 features and 4 fields
## Geometry type: MULTIPOLYGON
## Dimension: XY
## Bounding box: xmin: -90.42 ymin: 41.7 xmax: -82.41 ymax: 48.26
## Geodetic CRS: WGS 84
## # A tibble: 38 × 5
## # Groups: NAME [38]
## NAME LEGISLATOR PARTY hull_score
## <chr> <chr> <chr> [1]
## 1 27 "Jim Ananich" D 0.861
## 2 23 "Curtis Hertel, Jr." D 0.866
## 3 20 "Sean McCann" D 0.998
## 4 29 "Winnie Brinks" D 0.789
## 5 28 "Mark Huizenga " R 0.745
## 6 08 "Doug Wozniak " R 0.580
## 7 10 "Michael MacDonald " R 0.764
## 8 09 "Paul Wojno" D 0.846
## 9 13 "Mallory McMorrow" D 0.795
## 10 11 "Jeremy Moss" D 0.785
## # … with 28 more rows, and 1 more variable:
## # geometry <MULTIPOLYGON [°]>We can store these columns into a separate dataset, hull_scores_dataset_mi_senate_2011.
hull_scores_dataset_mi_senate_2011<- as_tibble(mi_senate_2011) %>%
select(NAME, LEGISLATOR, PARTY, hull_score)Observe the first ten scores:
## # A tibble: 38 × 4
## NAME LEGISLATOR PARTY hull_score
## <chr> <chr> <chr> [1]
## 1 27 "Jim Ananich" D 0.861
## 2 23 "Curtis Hertel, Jr." D 0.866
## 3 20 "Sean McCann" D 0.998
## 4 29 "Winnie Brinks" D 0.789
## 5 28 "Mark Huizenga " R 0.745
## 6 08 "Doug Wozniak " R 0.580
## 7 10 "Michael MacDonald " R 0.764
## 8 09 "Paul Wojno" D 0.846
## 9 13 "Mallory McMorrow" D 0.795
## 10 11 "Jeremy Moss" D 0.785
## # … with 28 more rowsFor example, calculate summary statistics by party:
## # A tibble: 2 × 2
## PARTY mean
## <chr> [1]
## 1 D 0.731
## 2 R 0.742On average the districts are similar in convex hull compactness. In spread, the standard deviations are similar:
## # A tibble: 2 × 2
## PARTY stand_dev
## <chr> <dbl>
## 1 D 0.166
## 2 R 0.1306.6 Accessing US Census data
Analyzing gerrymandering often requires assessing the demographic characteristics of electoral districts. The U.S. Census Bureau provides two primary types of data: (1) demographic characteristics of geographic areas, and (2) geographic boundary files (lines, points, and shapes) that define these areas. Several R packages facilitate access to Census data; here, I illustrate the use of the tidycensus package (Walker and Herman 2024; Walker 2023).
While the Census offers a wide range of data products, this example focuses on downloading 2022 American Community Survey (ACS) 5-year estimates at the state level19. These datasets can be readily merged with boundary files for legislative district maps, as described below.
Data are downloaded directly from the Census Bureau, which requires registration to access their data servers. The first step is to register for a free access code, specifically an API key: https://api.census.gov/data/key_signup.html. After registering and receiving the key, install and attach the tidycensus package. (This section of the text also makes use of tidyverse functions).
The API key is stored in your R environment with the census_api_key() function. You must reload the environment with readRenviron("~/.Renviron")) for the key to be available in your R session.
# not a working API key below
census_api_key("5c9a42d90596a472d3", install=TRUE)
readRenviron("~/.Renviron")Perhaps the most difficult part of working with Census Bureau data is identifying specific measures within any one data product. The sheer volume of variables count into the tens of thousands, a scale much larger than global development indicators from World Bank data. The tidycensus package provides a function load_variables() to download available measures from a specified product, in this case the 5-year estimates from the most recent ACS survey:
## # A tibble: 28,152 × 4
## name label concept geogr…¹
## <chr> <chr> <chr> <chr>
## 1 B01001A_001 Estimate!!Total: Sex by… tract
## 2 B01001A_002 Estimate!!Total:!!Male: Sex by… tract
## 3 B01001A_003 Estimate!!Total:!!Male:… Sex by… tract
## 4 B01001A_004 Estimate!!Total:!!Male:… Sex by… tract
## 5 B01001A_005 Estimate!!Total:!!Male:… Sex by… tract
## 6 B01001A_006 Estimate!!Total:!!Male:… Sex by… tract
## 7 B01001A_007 Estimate!!Total:!!Male:… Sex by… tract
## 8 B01001A_008 Estimate!!Total:!!Male:… Sex by… tract
## 9 B01001A_009 Estimate!!Total:!!Male:… Sex by… tract
## 10 B01001A_010 Estimate!!Total:!!Male:… Sex by… tract
## # … with 28,142 more rows, and abbreviated variable
## # name ¹geographyWithout a year= argument, the function downloads data from the most recent year available, which as of this writing is 2022. The datatable is saved as data frame variable_names, which consists of four columns: (1) name — alphanumeric identifier for each measure; (2) label — a specific explanation of the measure; (3) concept — a broader description of the measure; and (4) geography — the smallest geographic unit for which the measure is available, such as “tract”.
A quick way to identify variables is displaying the data table with View(variable_names). The search field within View() enables a general search across all spreadsheet. In the upper left-hand corner of the View() spreadsheet, the filter button applies a case-insensitive search to any of the chosen fields.
With filter() from the tidyverserse a smaller table of variables can be saved as a data table, based on a more precise search in specific fields of the data table. For example, to look for population figures, the search can focus on the concept column, saving these search results to another dataframe pop_search:
In the second line above, the str_detect() function from the stringr package in the tidyverse searches in the column concept for any matching patterns (case sensitive) to “Total Population”. It identifies 70 matches, stored in pop_search, which can be quickly scanned in View(pop_search). Figure 6.16 displays the first few rows of the variable table. Notice that the first row entry under the concept column is the entry “Total Population” without any further elaboration, while the rows below it reference population in “…Occupied Housing Units”, meaning these rows reference population counts within the specified housing units. The geography column shows these counts are available at the block level and higher. The entry in the first row under name, B01003_001 lists the variable name that will be used to collect data on total population within US States.

FIGURE 6.16: Excerpt of US Census Bureau variables in data table format, accessed through the spreadsheet viewer.
The function get_acs() will retrieve the ACS data, given a specified geographic level and the name of the variable, such as for US States: get_acs(geography = "state", variables ="B01003_001"). The Census Bureau organizes data on many geographic levels; for a complete list of geographies, see Walker (2023).
## Getting data from the 2018-2022 5-year ACS## # A tibble: 52 × 5
## GEOID NAME variable estimate moe
## <chr> <chr> <chr> <dbl> <dbl>
## 1 01 Alabama B01003_001 5028092 NA
## 2 02 Alaska B01003_001 734821 NA
## 3 04 Arizona B01003_001 7172282 NA
## 4 05 Arkansas B01003_001 3018669 NA
## 5 06 California B01003_001 39356104 NA
## 6 08 Colorado B01003_001 5770790 NA
## 7 09 Connecticut B01003_001 3611317 NA
## 8 10 Delaware B01003_001 993635 NA
## 9 11 District of Columbia B01003_001 670587 NA
## 10 12 Florida B01003_001 21634529 NA
## # … with 42 more rowsThe 52 observations include all states, Washington, DC and Puerto Rico. Notice the data table appears in long form; additional indicators would be appended to the end. A variable column records the name of each variable, while estimate records the indicator value. The column moe records the margin of error for the sample estimate.
An option for get_acs(), output="wide" will shift the data table to wide format. Additional variables are added as separate column entries. And mnemonic names can be added to the table in place of the default names. Collecting the names in c() modifies the variables= argument, such as variables = c(total_pop="B01003_001", black_pop="B01001B_001"), which would select and relabel the population total and population selecting solely ‘Black or African American’ as race.
get_acs(geography = "state",
variables = c(total_pop="B01003_001",
black_pop="B01001B_001"), output="wide")## Getting data from the 2018-2022 5-year ACS## # A tibble: 52 × 6
## GEOID NAME total…¹ total…² black…³ black…⁴
## <chr> <chr> <dbl> <dbl> <dbl> <dbl>
## 1 01 Alabama 5.03e6 NA 1326341 3804
## 2 02 Alaska 7.35e5 NA 23395 906
## 3 04 Arizona 7.17e6 NA 327077 4147
## 4 05 Arkansas 3.02e6 NA 456693 2289
## 5 06 California 3.94e7 NA 2202587 9304
## 6 08 Colorado 5.77e6 NA 233712 2900
## 7 09 Connecticut 3.61e6 NA 385407 3664
## 8 10 Delaware 9.94e5 NA 218266 2327
## 9 11 District of C… 6.71e5 NA 297101 1999
## 10 12 Florida 2.16e7 NA 3355708 10029
## # … with 42 more rows, and abbreviated variable names
## # ¹total_popE, ²total_popM, ³black_popE, ⁴black_popMIn wide format, the Census variables span across columns, with the selected column names. The function pulls not only the statistic estimates, but also the estimated margins of error for each, noted with E for estimate and M for margin of error appended to the end of each column. The estimates can be selected (along with the geographic identifiers) and saved in a new data table:
state_census<-get_acs(geography = "state",
variables = c(total_pop="B01003_001", black_pop="B01001B_001"),
output="wide") %>%
select(GEOID, NAME, total_popE, black_popE)## Getting data from the 2018-2022 5-year ACSThe table state_census records these observations:
## # A tibble: 52 × 4
## GEOID NAME total_popE black_popE
## <chr> <chr> <dbl> <dbl>
## 1 01 Alabama 5028092 1326341
## 2 02 Alaska 734821 23395
## 3 04 Arizona 7172282 327077
## 4 05 Arkansas 3018669 456693
## 5 06 California 39356104 2202587
## 6 08 Colorado 5770790 233712
## 7 09 Connecticut 3611317 385407
## 8 10 Delaware 993635 218266
## 9 11 District of Columbia 670587 297101
## 10 12 Florida 21634529 3355708
## # … with 42 more rowsThe US Census Bureau also maintains its own set of geographic Shapefiles20, which can be merged with census data downloaded from tidycensus package or, in some cases, downloaded directly through tidycensus by adding the argument geometry=TRUE. For example, get_acs(geography = "state", variables = c(total_pop="B01003_001", black_pop="B01001B_001"), output="wide", geometry=TRUE) would download State (including Washington, DC and Puerto Rico) line coordinates for visualization and further manipulation like other map objects reviewed in this chapter. The complementary tigris package (R-tigris?) automates the importation of the Census geographic datafiles; alternatively, the files can be downloaded directly from the Census Bureau website and merged with the data tables on the GEOID column.
Resources
Many units of government maintain Geographic Information Systems (GIS) portals for distributing geospatial data; for example, Michigan’s site is https://gis-michigan.opendata.arcgis.com/.
The boundary lines for South Africa from this chapter are from GeoQuery at AidData https://www.aiddata.org/geoquery, which hosts many other geospatial datasets.
GeoQuery includes boundary line files from https://www.geoboundaries.org (Runfola et al. 2020), another comprehensive source.
Other comprehensive repositories include the University of California at Berkeley GeoData library, https://geodata.lib.berkeley.edu/. TIGER/Line Shapefiles from the US Census Bureau are available from https://www.census.gov/geographies/mapping-files/time-series/geo/tiger-line-file.html
For Geocoding addresses in the USA, there is the Texas A&M Geoservices https://geoservices.tamu.edu/Services/Geocode/Interactive/.
There are many additional packages for visualizing and manipulating geospatial data, following from the methods introduced within this chapter. For further reading see Lovelace, Nowosad, and Muenchow (2019) (online at https://r.geocompx.org/) and Walker (2023) (online at https://walker-data.com/census-r/index.html).
Additional election and spatial datafiles are available from the Harvard Election Data Archive (https://projects.iq.harvard.edu/eda) and MIT Election Data + Science Lab (https://electionlab.mit.edu/).
6.7 Exercises
For the following exercises, prepare a .Rmd file with the code and responses to the questions below, knitted into an .html file for interactive maps, or PDF or Word document for static maps, as required by the question.
Create a red-blue election map from the 2011 Michigan State Senate districts, either highlighting the winning State Senate candidate in red or blue colors, or display the margin of the vote percent from red through blue. To merge the vote data onto the State Senate legislative district maps, first change the district name in the Senate maps for 2011 from character to numeric
mi_senate_2011 <- mi_senate_2011 %>% mutate(NAME = as.numeric(NAME)). Then merge the senate wide-formatted data table MI_state_senate_2014_wide onto the map data mi_senate_2011 withleft_join(), mergingby=c("NAME"="DistrictNumber")). Create an indicator to display either the winning candidate in red or blue to display with scale_fill_manual, or a measure of the vote margin to display with scale_fill_gradient2.Using the polygon data for administrative wards in South Africa, ZAF_ADM4.geojson and corresponding air pollution data, subset to a city. With an interactive leaflet map, display the variation in air pollution across the wards. Prepare the map as a presentation graphic with clearly labeled parts; in a paragraph, explain what the variation shows and any interesting features you see.
Repeat the steps for the map of South Africa, but apply the steps for a static map created with ggplot2. Be sure to include both a base layer and the polygons displaying variation in air pollution.
Identify a US State redistricting plan in a Shapefile (.shp file) or GEOjson file; visualize the districts and calculate a compactness measure for each district. Summarize the variation in compactness measures, given a categorical characteristic of the districts such as party affiliation of the election winner.
Pick a US State; download and clean the US County-level presidential election votes by County. Create a County-level map of the presidential election results. Contrast the map with a Cartogram constructed on the same geography. Discuss the Cartogram alongside the prior map, explaining the different features of the Cartogram compared to the traditional election map.
References
As a last resort, if no other map projection works, try
epsg:4326, which is a pseudo-projection, an “equirectangular” projection (see https://en.wikipedia.org/wiki/Equirectangular_projection) orepsg:3857the usual projection for transportation maps.↩︎See https://www.census.gov/data/developers/data-sets/acs-5year.2022.html#list-tab-1806015614↩︎
See https://www.census.gov/geographies/mapping-files/time-series/geo/tiger-line-file.html↩︎