Chapter 7 Scaling and Clustering for Pattern Detection
Chapter 7 reviews the use of distance metrics for summarizing and exploring relationships between observations.
Learning objectives and chapter resources
By the end of this chapter you should be able to: (1) describe conceptually the use of multi-dimensional scaling (MDS) as a tool for analyzing data; (2) prepare a data table and construct a matrix of Euclidean or Manhattan distance metrics; (3) apply functions for estimating and evaluating nonmetric MDS solutions; (4) interpret a measure of model goodness of fit; (5) contrast the use of distance metrics in MDS with hierarchical clustering; and (6) interpret a dendrogram. The material in the chapter requires the following packages: smacof (Mair, De Leeuw, and Groenen 2022), which will need to be installed, as well as ggrepel (Slowikowski 2023), and tidyverse (Wickham 2023b). The material uses the following datasets poll_ft.csv, co_na_h_votes_117_wide.csv, co_117_euc_distances.csv, and s_memb_votes_117_wide.csv from https://faculty.gvsu.edu/kilburnw/inpolr.html.
Spatial politics and distance metrics
We frequently conceptualize politics in spatial terms. The ubiquity of variations on the phrase ‘liberal to conservative spectrum’ captures this intuition. Spatial representations of politics are a kind of political science ‘brand’, encompassing how the discipline explains lines of political conflict through one- or two-dimensional figures (Brady2011?). An analytic method for taking data and generating insight into spatial politics through visualization is multidimensional scaling (MDS) — a technique closely tied to spatial theories of politics and one that political scientists have actively developed and refined (Armstrong et al. 2020; William G. Jacoby and Armstrong 2014; Brady, Collier, and Box-Steffensmeier 2011).
In Chapter 7, we review the use of MDS, along with a related method, cluster analysis. There are many varieties of these methods; our discussion is limited to an overview of nonmetric MDS (Rabinowitz 1975) and ‘hierarchical’ clustering (Bartholomew et al. 2008). While related, each provides distinctly different insight into the same data. We will review the conceptual foundations of MDS and cluster analysis with the creation of ‘distance metrics’, the primary data input for these procedures, followed by three examples. First, we will apply MDS to the spatial configuration of the American public’s feelings toward political candidates and figures. Second, we will apply MDS to explore the spatial relationships between legislators in the U.S. Congress as revealed through roll call voting. Third, we will contrast the insights from MDS with a cluster analysis of the same data sources.
7.1 Introduction to multidimensional scaling
Multidimensional scaling procedures are a graphical, data visualization focused method of analyzing data. Often the purpose is exploratory, to observe patterns of similarity between subjects of political interest, such as the voting behavior of legislators or an electorates’ feelings toward political figures. Just about any dataset composed of measures of a common set of observations could be analyzed through MDS, such as country-level measures of political and economic development. Whatever the input source data, the analytical output leads to a dimensional representation of the similarity among the observations.
An example of such a figure – a typical product of an MDS analysis – appears in Figure 7.1. The figure displays in two dimensions the patterns of feeling thermometer scores toward political figures and groups in the 2004 ANES survey; it is a typical ‘output’ of an MDS analysis, a two-dimensional scatterplot, given the input of individual-level thermometer scores. The figure shows the location of the subjects, where subjects grouped closer together elicited more similar feelings from the electorate. Based on input matrix summarizing the patterns of dissimilarity between the feeling thermometer scores across the figures and groups, the MDS algorithm constructed a set of two-dimensional coordinates for each one, so that the coordinates mirror the dissimilarities as much as possible.
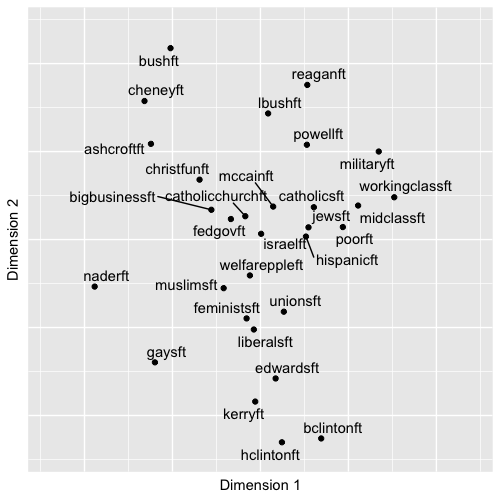
FIGURE 7.1: Nonmetric multidimensional scaling (MDS) plot of feeling thermometer ratings from the 2004 ANES survey, reduced to two dimensions. The plot arranges political figures and social groups based on similarity in respondents’ ratings: groups with more similar ratings appear closer together. The familiar partisan and ideological fault lines of American politics emerge, with political figures clustering along ideological directions away from the center, where social groups tend to cluster.
The MDS input data is a square matrix of dissimilarities, measures that quantify the degree of difference between objects of political interest, considered in pairs. A matrix of dissimilarity data from feeling thermometers could be measures that summarize how differently the public feels toward political figures. There are two basic varieties of MDS procedures: metric and nonmetric. A metric MDS procedure makes interval-level assumptions about the input dissimilarities, finding output distances that reflect the numeric score dissimilarities in the input data. A nonmetric MDS procedure makes only ordinal-level assumptions about the input dissimilarities. In effect the input dissimilarity scores between objects of interest are rank ordered, from least to most similar, and the algorithm finds an optimal translation of the rank-ordered dissimilarities into distances. Below I conceptually review the steps in a nonmetric MDS. A concise and technical introduction to metric and nonmetric is Jacoby (1991) or Jacoby and Ciuk (2018). Nonetheless, both methods start with the construction of dissimilarity matrices. Two commonly used metrics for summarizing dissimilarities are Euclidean and Manhattan distances.
7.2 Euclidean and Manhattan distances
Perhaps the most common dissimilarity measure used in MDS is the Euclidean distance metric. The distance measures the straight line path between two points in a multidimensional space. Figure 7.2 illustrates a Euclidean distance between two points (or objects) in a two-dimensional space, X and Y. The Euclidean distance is based on the familiar Pythagorean theorem, \(a^2 + b^2 = c^2\), describing the length of the hypotenuse of a right triangle on these two dimensions. Figure 7.2 displays the Euclidean, straight line distance between the two points, calculated from the squared sum of the distances between each point on the X and Y dimensions. Working through the arithmetic in R illustrates how it works.
## [1] 5.831The distance can be generalized to any number of dimensions and points. If we added a third point and a third dimension, identified p , q, and r:
We can combine rows of the points together (rbind()) into a matrix matx and apply the distance function dist() to calculate the Euclidean distance:
## [,1] [,2] [,3]
## p 6 5 7
## q 1 2 10
## r 2 5 12## p q
## q 6.557
## r 6.403 3.742The result is a Euclidean distance matrix.
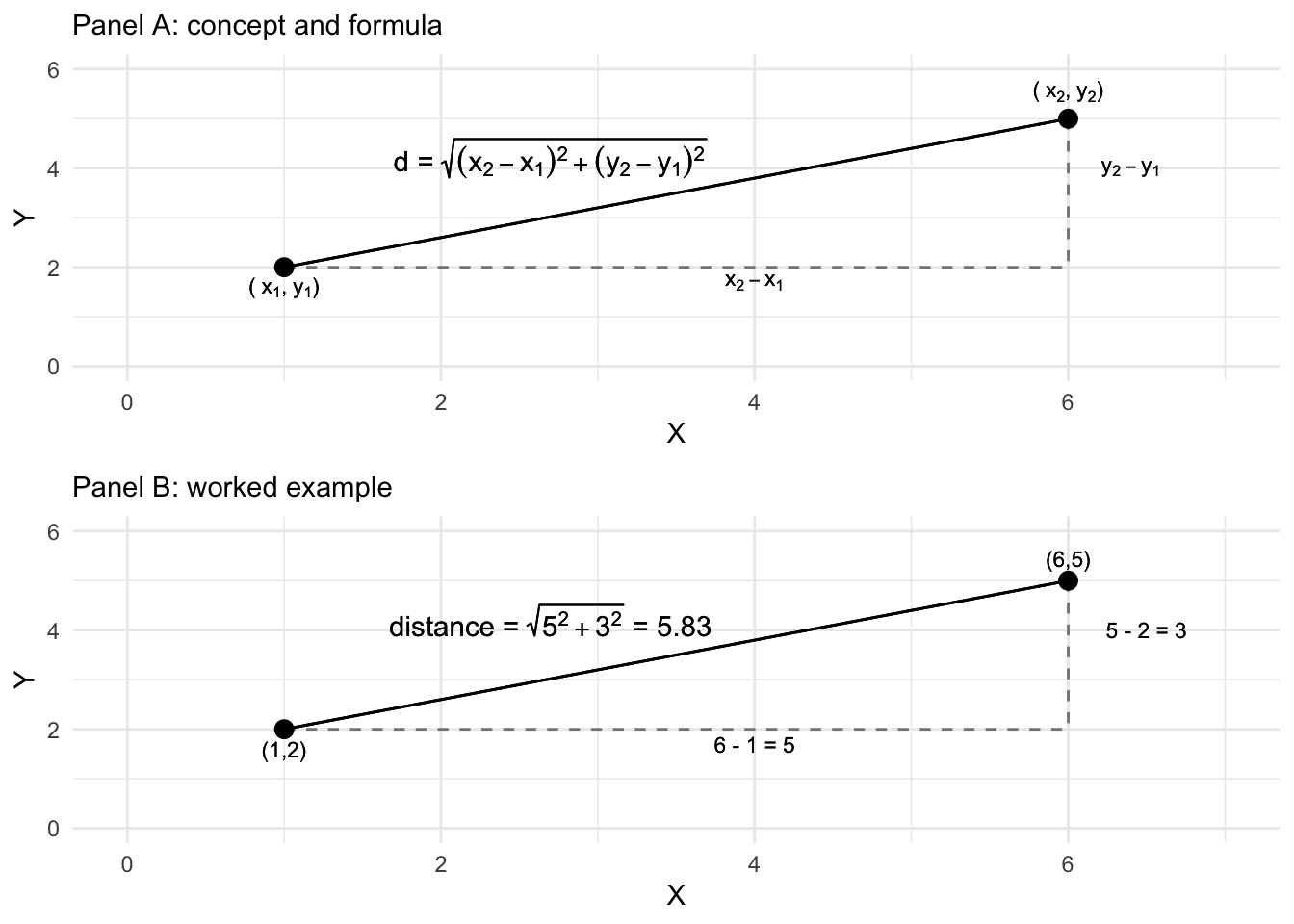
FIGURE 7.2: Euclidean distance formula and calculation of the distance between two points on two dimensions, X and Y.
Another way of calculating the distance is via a Manhattan or ‘city block’ distance. Figure 7.3 displays how the Manhattan distance is calculated like walking city blocks, over and up or down. The Manhattan distance is the sum of the absolute difference between the dimensions. For the distance between p and q on the two dimensions, the difference calculated in R is 8: abs(6-1) + abs(5-2). Adding a distance="manhattan" argument to dist() creates the distances for matx:
## p q
## q 11
## r 9 6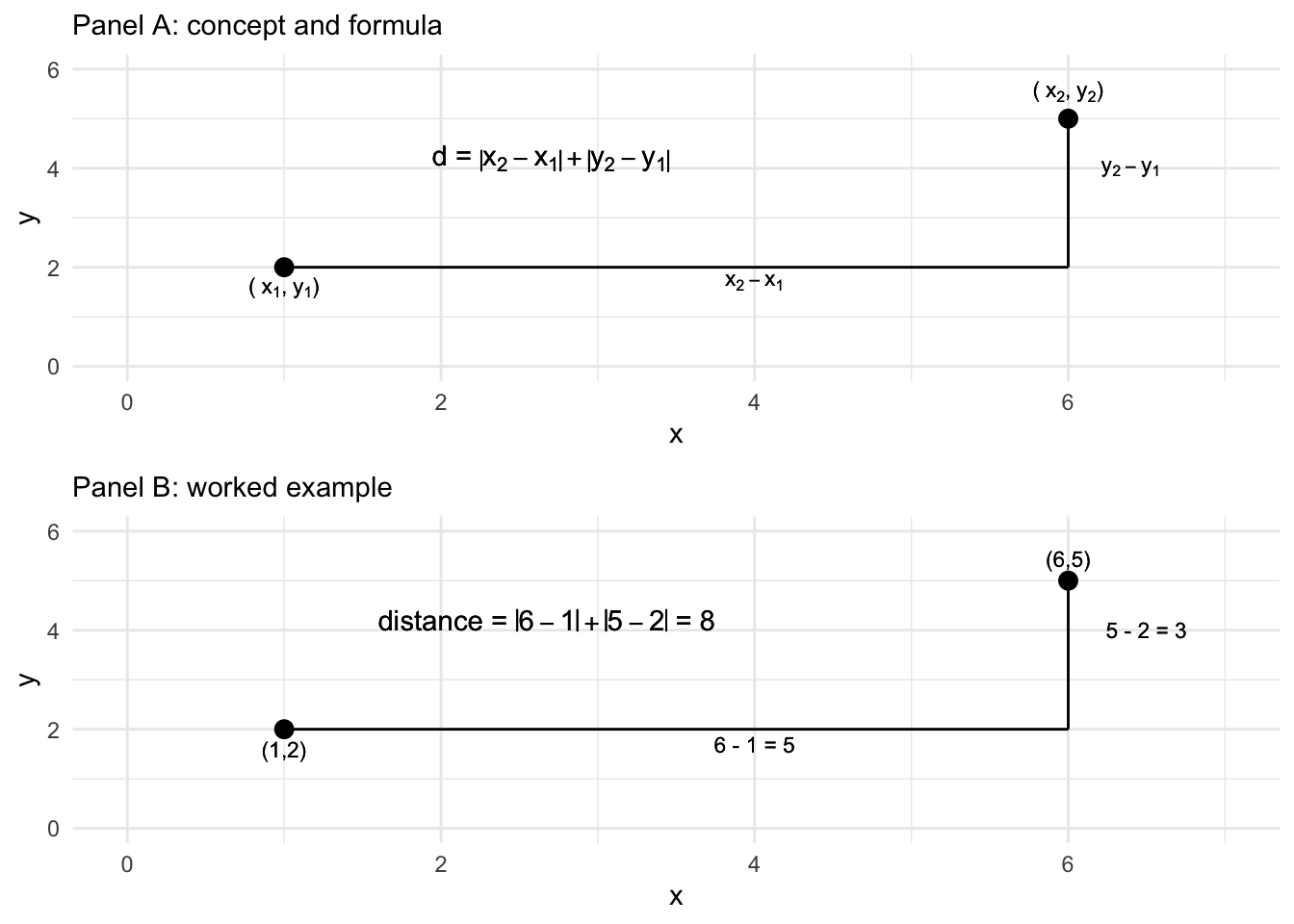
FIGURE 7.3: Manhattan ‘city block’ distance formula and calculation of the distance between two points on two dimensions, X and Y.
Instead of abstract points, in an MDS analysis, distance matrices are created with measurements on political objects of interest — for example, for feeling thermometers, the dimensions (like X and Y) are each a survey respondent’s rating of a candidate, or for legislators, the dimensions are the roll call votes. Give a matrix of dissimilarity, the MDS algorithm translates the dissimiliarities into distances.
In a nonmetric MDS, the algorithm accounts for the ordinal arrangement of the dissimilarities starting with “target distances” (or “disparities”), the distances that the algorithm tries to reproduce in the low-dimensional space. The target distances are a new distance matrix, one that preserves the rank order of pairs of objects in their similarity, but not necessarily the exact numerical value of the original matrix of distances. The goal is to find a one- or two-dimensional configuration of the points (as the output visualization) where the actual distances between points closely approximate these target distances. The algorithm focuses on preserving the rank order of the dissimilarities, ensuring that objects perceived as more similar remain closer together in the plot. The fit of the model is evaluated using the function applied by the algorithm to find the configuration, referred to as the “Stress function”, which measures the degree of mismatch between the actual distances and the disparities, with lower stress indicating a better fit. The fit statistic is discussed further below. For now, we will work through an example in R.
7.3 Scaling feelings toward political figures and groups
We will work through an example of an MDS analysis of feeling thermometer scores poll_ft.csv, to illustrate how the procedure works. To begin, we will load two packages, tidyverse and ggrepel (for labeling graphics), then read in the dataset and store it as object polfigures. We use the read_csv() function from the tidyverse package:
Once it is stored as polfigures, we will remove the columns that do not contain feeling thermometer scores, to simplify the process of applying a distance metric to the data.
polfigures<- polfigures %>%
select(-gender, -campint, -fair, -prezapp, -libcon, -party, -partyid,
-race, -conservatives, -abor, -educ)## # A tibble: 1,212 × 30
## bushft kerryft naderft cheneyft edwardsft lbushft
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 70 85 0 50 50 NA
## 2 40 85 NA 40 70 60
## 3 100 50 50 100 50 100
## 4 50 60 60 40 70 60
## 5 100 0 50 85 0 100
## 6 60 30 100 15 30 50
## 7 85 15 40 70 50 70
## 8 50 70 85 60 100 70
## 9 30 70 15 15 60 85
## 10 100 0 0 100 0 100
## # … with 1,202 more rows, and 24 more variables:
## # hclintonft <dbl>, bclintonft <dbl>,
## # powellft <dbl>, ashcroftft <dbl>, mccainft <dbl>,
## # reaganft <dbl>, hispanicft <dbl>,
## # christfunft <dbl>, catholicsft <dbl>,
## # feministsft <dbl>, fedgovft <dbl>, jewsft <dbl>,
## # liberalsft <dbl>, midclassft <dbl>, …Now the dataset consists solely of 30 feeling thermometer scores, queried from the 1,212 respondents to the 2004 ANES survey, a representative cross-section of the U.S. citizenry, 18 years of age or older by the November 2004 election day. (See the Appendix for data details.) The scores for each political figure or social group is rated on the feeling thermometer scale from 0 to 100, the figure of group identified by name, such as reaganft for Ronald Reagan. Missing values, NA, correspond to “don’t know” type responses or any other reason in which a rating was not recorded. Observing the first five rows and columns:
## # A tibble: 5 × 5
## bushft kerryft naderft cheneyft edwardsft
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 70 85 0 50 50
## 2 40 85 NA 40 70
## 3 100 50 50 100 50
## 4 50 60 60 40 70
## 5 100 0 50 85 0The dist() function to create the summary distance measures between the candidates requires the input matrix to be transposed from its current form. The candidates are currently on the columns, and survey respondent raters are on the rows. The function requires that the ‘stimuli’, the objects to be assessed for differences, appear on the rows. A transpose function t() will switch rows and columns:
## [,1] [,2] [,3] [,4]
## bushft 70 40 100 50
## kerryft 85 85 50 60
## naderft 0 NA 50 60
## cheneyft 50 40 100 40The transpose t() function is necessary to transpose the input dataset, moving column (candidates) to rows and each survey respondent to the columns.
Notice the NA value naderft from the survey respondent in the second column. The dist() function handles missing values by simply dropping any pairwise comparisons that involve NA values. So for example, across the first four survey respondents or ‘dimensions’ of comparison, the Euclidean distance between naderft and kerryft is \(\sqrt{(85-0)^2 + (50-50)^2 + (60-60)^2}\), dropping from the calculation the undefined difference between \((85-\)NA\()^2\). From among these four survey respondents, the distance between naderft and kerryft would be based on comparisons between three respondents, while comparisons between kerryft and bushft for example would be based on all four. In addition to dropping any pairwise comparisons involving an NA value, the dist() function also applies a scaling adjustment to any distance calculations in which the number of pairwise comparisons used are less than the total possible number of comparisons.
To observe how the scaling adjustment works, we will apply the dist() function to this \(4 \times 4\) subset of the data.
## bushft kerryft naderft
## kerryft 69.64
## naderft 100.00 98.15
## cheneyft 22.36 78.42 84.85Notice in the matrix of distances, the Euclidean distance between kerryft and naderft is 98.14955. This distance differs from the result of 85 from sqrt((85-0)^2 + (50-50)^2 + (60-60)^2). The difference is accounted for by the adjustment factor, \(\sqrt{\frac{n}{k}}\), where \(n\) is the total possible number of comparisons, the total number of ‘dimensions’ or respondent ratings if there were no NA values. Then \(k\) is the number of non-NA comparisons. The weight is multiplied by the Euclidean distance; for the distance between kerryft and naderft for these four survey respondents, the scaled distance would be \(\sqrt{\frac{4}{3}} \times 85\), or
## [1] 98.15The result matches the distance in the matrix of six entries on the four columns from the dist() function. With the full matrix of scores, we apply the transpose function inside the dist() function to create the input distance matrix. The result is stored as dissimat:
The result is a ‘distance object’, dissimat, a \(30 \times 30\) matrix containing (by default) Euclidean distances between each feeling thermometer subject. While the default is Euclidean distance, it can be changed with the method= argument, such as dist(t(polfigures), method='manhattam'). Researchers usually refer to these matrices as ‘dissimilarity matrices’ or ‘dissimilarity measures’ to avoid confusion with the output of an MDS algorithm, a visualization translating these dissimilarities into distances in the visualization.
To view a snippet of the dissimilarity matrix, we first convert it to a matrix and then view the first few rows and columns:
## bushft kerryft naderft cheneyft edwardsft
## bushft 0.0 1878.6 1429 782.9 1790.1
## kerryft 1878.6 0.0 1220 1678.8 651.4
## naderft 1429.5 1220.4 0 1251.3 1208.0
## cheneyft 782.9 1678.8 1251 0.0 1642.7
## edwardsft 1790.1 651.4 1208 1642.7 0.0The subscripts [1:5, 1:5] refer to row and column [r, c] selections, selecting the first through fifth row. The matrix is symmetric and the main diagonal entries displaying the distance from one political figure on a column to the same political figure on the row is, of course, 0. Across the first row, the distance between bushft and kerryft is 1878.63. The distance between cheneyft and bushft is 782.869. Again, these are the scaled distances between pairs of feeling thermometers, calculated across all available pairs of non- NA feeling thermometer scores.
The object dissimat is the input into the MDS algorithm that translates these dissimilarities into distances. Using the smacof package (Mair, De Leeuw, and Groenen 2022), the mds() function will find a set of output coordinates for the input dissimilarity matrix, for a given number of dimensions. The function requires that we specify the input matrix (in this example, dissimat), the number of dimensions (ndim=) and for a nonmetric MDS, type="ordinal". Install the package if necessary, install.packages("smacof").
The results will be stored as object nmds_results:
Typing the name of the object nmds_results reveals details about how the algorithm, in particular a measure of ‘badness of fit’, which we will review further below. The main result of the mds() function is the set of dimensional positions of the feeling thermometers, which is stored as the configuration of points, nmds_results$conf. Typing this object out, or viewing the top six rows with head():
## D1 D2
## bushft 1.0878 -0.51103
## kerryft -0.9208 -0.02963
## naderft -0.2673 -0.94219
## cheneyft 0.7874 -0.65896
## edwardsft -0.7895 0.08626
## lbushft 0.7167 0.04366The output displays the positions of the thermometer objects, political figures and groups, on the two dimensions, labeled D1 and D2. Visualizing these configurations is the end goal of the MDS, so the next step is to save the configurations to a dataframe and visualize it:
As a dataframe, it is organized into rows and columns:
## D1 D2
## bushft 1.0878 -0.51103
## kerryft -0.9208 -0.02963
## naderft -0.2673 -0.94219
## cheneyft 0.7874 -0.65896
## edwardsft -0.7895 0.08626
## lbushft 0.7167 0.04366Note the dataframe contains row names of the thermometers rather than a column within the dataframe; these are row names, stored as row.names() within it. The results plotted as points with the label row names in ggplot(). Figure 7.1 displays the MDS algorithm’s solution to the problem of finding an arrangement of the feeling thermometers in a two-dimensional X - Y plot, so that the relative distances between each of the points preserves as much as possible the rank order of the disparities calculated from the matrix of Euclidean distances. The ggplot() code to generate the figure appears below. The graphic suppresses the numeric placeholders for the scaling solution, as the coordinates of the points do not have inherent meaning on their own.
ggplot(nmds1) +
geom_point(aes(x=D2, y=D1)) +
geom_text_repel(aes(x=D2, y=D1, label=row.names(nmds1))) +
scale_y_continuous(limits = c(-1.2, 1.2))+
scale_x_continuous(limits=c(-1.2, 1.2))+
labs(x = "Dimension 1", y = "Dimension 2") +
theme(axis.text.x = element_blank(),
axis.ticks.x = element_blank() )+
theme(axis.text.y = element_blank(),
axis.ticks.y = element_blank() )The figure visualizes the extent to which figures and groups tend to elicit similarly warm or cool feelings; figures such as these date back to the first thermometer items included in the ANES; for example, see Rusk (1972). In interpreting MDS solutions, the key is the relative spacing of the points, the direction or clustering of points — and not to focus exclusively on the movement along the X and Y axes defined in the graphic. Overall, the arrangement in Figure 7.1 reflects a familiar clustering of groups and figures associated with the ‘left’, ‘right’ and the Democratic and Republican parties, respectively.
As a map of the electorate’s feelings toward figures and groups, clearly there are clusters of Democratic and Republican figures anchoring the upper and lower portions of the graph, perhaps reflecting a partisan ideological dimension of comparison. There are clusters within these regions of the graph, figures and groups associated together, such as the upper-left quadrant clustering Bush, Cheney, Ashcroft, and “Christian Fundamentalists”. The social groups tend to cluster in the middle of the graph, perhaps reflecting a lack of polarized feeling toward each. Note that because the interpretation is about the relative position of the points toward each other, the points can be rotated geometrically around the graph if it helps interpretation; scaling texts such as Armstrong and Bakker (2020) and Jacoby (William G. Jacoby 1991) explain how.
Assessing MDS model fit
Before presenting the analysis of roll call votes, there are two additional concerns that must accompany any MDS analysis: how ‘good’ of a fit is the dimensional arrangement of observations? And how many dimensions should be visualized? The “Stress” measure of model fit, and an additional figure – a “Shepard diagram” — help to answer these questions.
The Stress statistic, often referred to as “Stress type 1” to differentiate it from other measures is a standard for assessing how well a visual configuration of the observations reflects the dissimilarity input matrix (Bartholomew et al. 2008). While not technically an average, it can be interpreted as the average deviation between the disparities and the fitted distances in the figure. Typing the name of the MDS object, nmds_results, reveals the Stress measure and the basic configuration of the model.
##
## Call:
## mds(delta = dissimat, ndim = 2, type = "ordinal")
##
## Model: Symmetric SMACOF
## Number of objects: 30
## Stress-1 value: 0.092
## Number of iterations: 36The Stress measures how well the distances in the solution match the dissimilarities from the input data. It ranges from 0 to 1, where lower values indicate better fit, thus it is a ‘badness of fit’ measure. If the arrangement of the fitted distances between the thermometers in the one- or two-dimensional space perfectly reflects the rank=ordered distances of the thermometers in the input matrix, then the Stress value would be 0, a perfect fit. From there, some guidelines are .05 is a “good” fit, while .2 or higher is a “poor” fit (Bartholomew et al. 2008). There is a tradeoff between better fit through higher dimensionality versus interpretability. In the example of the feeling thermometers, the Stress value shows a good fit, which could be improved with an additional dimension at the expense of parsimony. Researchers typically plot configurations of one to two dimensions (William G. Jacoby and Ciuk 2018).
Shepard diagrams
A Shepard diagram is a diagnostic scatterplot for assessing the fit of an MDS (Shepard 1962). The plot displays information about the fit between the observed dissimilarities or disparities (the input data) and the fitted distances (the output figure). For each pair of points, on the X-axis the figure plots the original dissimilarities or disparities, the ‘target distances’ that represent the ordinal rank order of similarity between the pairs. The Y-axis plots the fitted distances. If the model fits perfectly — fitted distances match dissimilarities exactly – the points would line up on a straight 45-degree diagonal line from the origin.
The plot() function extracts the information from nmds_results , specifying plot.type="Shepard".
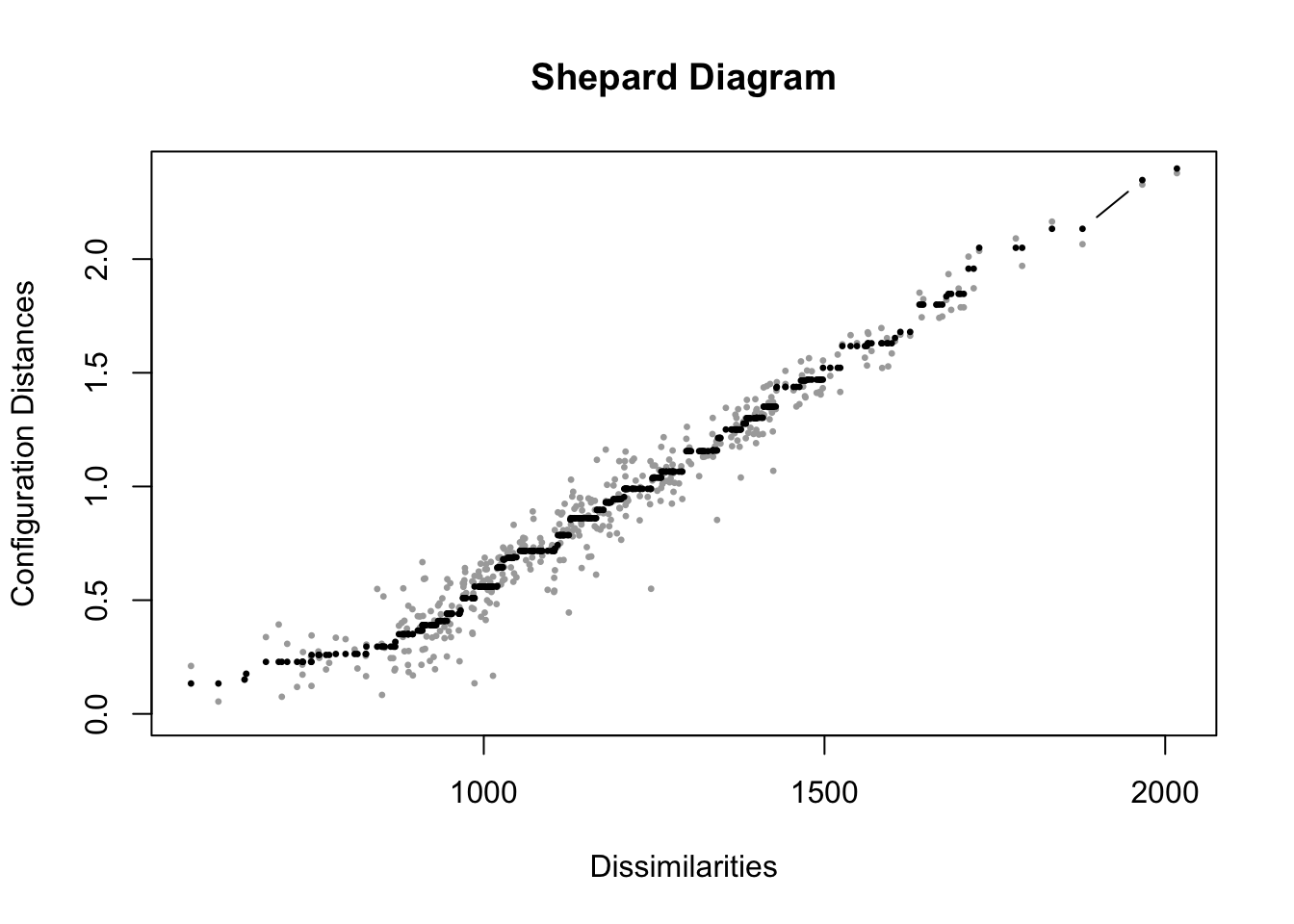
FIGURE 7.4: Shepard diagram for the nonmetric multidimensional scaling (MDS) solution of feeling thermometer ratings from the 2004 ANES, in two dimensions. The plot compares original dissimilarities to the distances in the MDS configuration.
In Figure 7.4, the diagram displays in gray points measurements on pairs of points, the input dissimilarities on X and the fitted distances in the output on Y. As would be expected from a Stress statistic of .092, the fit is not perfect, but the model fits somewhat well, with points clustered along the 45-degree line, although clearly for lower dissimilarities the fit is worse. The spread of points at the lower left side of the graph corresponds to the difficulty in scaling distances over two dimensions for the points with low dissimilarity. With less spread, as dissimilarity increases, fit improves. This contrast makes sense, given that for social groups scaled relatively close together, the algorithm was less successful in finding an optimal arrangement of the points, compared to the more polarizing cluster of political figures toward the edges of the output visualization.
The black points on the Shepard diagram represent the transformed dissimilarities, or disparities, which serve as the target distances for the MDS algorithm. These points reflect the idealized monotonic fit, preserving the rank order of the original dissimilarities. Notice that, from left to right, the black points either increase or remain constant, but never decrease, ensuring the monotonic relationship. Similar to the imaginary 45-degree line in metric MDS, the grey points, which represent the actual distances in the low-dimensional solution, should lie as close as possible to the black points for a good fit. The components of a Shepard diagram can be recovered from the MDS solution object, mdsgroup_results contains additional information about the MDS solution, accessible as “variables” within the object names(mdsgroup_results), with $ and the specific item. See the documentation for the smacof package.
7.4 Scaling roll call votes in the US Congress
Voting in legislatures is central to the study of politics. Models of voting behavior have a lengthy history in political science (K. T. Poole 2005). Roll call votes in US Congress are votes in which each member’s position (‘yea’, ‘nay’, or ‘present’) is individually recorded, for everything from motions and amendments to votes on final passage of legislation. The recorded votes are entered into the official Congressional Record. Interest groups base their ratings of legislators on these votes. The most prominent estimates of legislator ideology, ‘DW-NOMINATE’ scores, are based on roll call votes (K. T. Poole 2005). We will analyze votes from an MDS perspective, to visualize patterns of voting – differences between party caucuses and individual members.
Roll call votes are from the 117th US Congress (2021 to 2023). We first work through the process of tidying the data to prepare a matrix of votes for the mds() algorithm. While useful for practicing data skills, this step can be skipped, and the matrix of votes can be downloaded directly from the textbook’s website. Or, to practice data tidying and MDS analysis skills, download the full datafiles from Voteview.com (Lewis et al. 2023). For each Congress, Voteview organizes the data into three files: one for the voting records, a second for the members, and a third for descriptions of the roll call votes. We will first work with the votes and members’ data, then the roll calls to find specific type of legislation. The two datasets used to create the matrix of votes are HS117_votes.csv and HS117_members.csv, both of which include the House and Senate.
We will first work with Euclidean distances, and to keep the data manageable at first limit it to the Colorado delegation, then examples with the full House and Senate, illustrating properties of the Manhattan distance metric. Either start with the Voteview datafiles, or skip below to the matrix mds() input files beginning with co_117_euc_distances.csv.
Read in the votes data:
Familiarize yourself with the contents of it. We subset it to four columns:
Next we recode the numeric values for the ‘yeas’, ‘nays’, present, and absent votes. The ‘nays’ are scored at 0, ‘yeas’ at 1, and to make it easier to recall, 5 for present and 10 for absent.
HS117_votes <- HS117_votes %>%
mutate(cast_code = case_when(
cast_code==6 ~ 0,
cast_code==1 ~ 1,
cast_code==7 ~ 5,
cast_code==9 ~ 10))Try table(HS117_votes$cast_code) to observe the values for votes cast. Next we read in the data on members:
The data table contains demographic information about each member, as well as an ideology score (K. T. Poole and Rosenthal 2006). The key field in the members’ data is a unique identifier for each member, icpsr. The member data needs to be merged with the votes. We want, for each row of votes in HS117_votes, to have the member information appended as additional columns matched to icpsr. We use a right_join() function to merge the votes and members, saving the new merged dataset as hs_memb_votes_117.
hs_memb_votes_117 <- HS117_members %>%
select(icpsr, bioname, state_abbrev, party_code) %>%
right_join(HS117_votes, by="icpsr") %>%
select(chamber, bioname, party_code, state_abbrev,
cast_code, rollnumber, icpsr)In the language of mutating joins in the tidyverse (Wickham and Grolemund 2016), HS117_members is the X, and HS117_votes is the Y. So we would like X matched to Y. There are multiple matches from member information to their row-wise record of votes, identified by icpsr. So a warning message will appear letting us know that these multiple matches did in fact occur.
The Voteview data includes mock votes from public positions taken by presidents. Inspect the dataset to observe the presidents in the first few rows. We will remove the presidents:
Then we create a new dataset for House votes: work with votes from the House, extracting the House chamber votes to save it as h_memb_votes_117.
In the House, there are 996 possible votes they could have taken. (Enter table(h_memb_votes_117$bioname) to observe the count of Representatives and votes. We want to limit the data to just those representatives serving a full term. So we filter the data to all representatives with exactly 996 rows:
To limit the data and make it more manageable for learning MDS, we subset it to Colorado:
Enter co_h_votes_117 at the prompt to familiarize yourself with it. For labeling the output we need to create a simple label with name, party, and State, which we will use with the entire House and Senate as well.
We use the separate() function on the bioname column, specifying the sep=", " as the place to separate the name. Notice the white space after the comma, which prevents a leading white space appended to the first name; remove=FALSE.
Now the bioname column is separated into parts:
## # A tibble: 6,972 × 7
## last_n…¹ first party…² state…³ cast_…⁴ rolln…⁵ icpsr
## <chr> <chr> <dbl> <chr> <dbl> <dbl> <dbl>
## 1 LAMBORN Doug 200 CO 0 1 20704
## 2 LAMBORN Doug 200 CO 1 2 20704
## 3 LAMBORN Doug 200 CO 0 3 20704
## 4 LAMBORN Doug 200 CO 0 4 20704
## 5 LAMBORN Doug 200 CO 0 5 20704
## 6 LAMBORN Doug 200 CO 1 6 20704
## 7 LAMBORN Doug 200 CO 0 7 20704
## 8 LAMBORN Doug 200 CO 1 8 20704
## 9 LAMBORN Doug 200 CO 1 9 20704
## 10 LAMBORN Doug 200 CO 1 10 20704
## # … with 6,962 more rows, and abbreviated variable
## # names ¹last_name, ²party_code, ³state_abbrev,
## # ⁴cast_code, ⁵rollnumberNext we will change the party_code to a “D” or “R” and combine the last_name, state_abbrev, and party_code together, and then drop the remaining first and icpsr columns:
co_h_votes_117<- co_h_votes_117 %>%
mutate(party_code = case_when(
party_code == 100 ~ "D",
party_code == 200 ~ "R")) %>%
unite(name, c("last_name", "state_abbrev", "party_code")) %>%
select(-first, -icpsr)At this point we have to decide how to handle the votes cast that are not ‘yeas’ and ‘nays’, the problem being that there is no order or at least ordinal scale that links these votes with a vote of ‘present’ or an absence from voting. –A vote of ‘present’ or an absence is not meaningfully higher or lower than the ‘yeas’ and ‘nays’.
## # A tibble: 4 × 3
## cast_code n prop.
## <dbl> <int> <dbl>
## 1 0 2284 0.328
## 2 1 4571 0.656
## 3 5 1 0.000143
## 4 10 116 0.0166There is only one ‘present’ vote, and 116 absences, about 1.6 percent of the total. We could count up presences and absences by Representative:
co_h_votes_117 %>%
group_by(name) %>%
summarize(summary_absences = sum(cast_code == 10, na.rm = TRUE)) %>%
arrange(desc(summary_absences))## # A tibble: 7 × 2
## name summary_absences
## <chr> <int>
## 1 BUCK_CO_R 55
## 2 BOEBERT_CO_R 24
## 3 LAMBORN_CO_R 20
## 4 CROW_CO_D 6
## 5 DeGETTE_CO_D 5
## 6 PERLMUTTER_CO_D 5
## 7 NEGUSE_CO_D 1Or change the cast_code to 5 to observe Boebert cast the lone ‘present’.
We will calculate the distance metrics between the Representatives while converting the ‘present’ (5) and absent (10) votes to NA values:
co_na_h_votes_117 <- co_h_votes_117 %>%
mutate(cast_code = case_when(
cast_code %in% c(5, 10) ~ NA,
TRUE ~ cast_code))Inspect the dataset to observe the NA values. Next we pivot the data, converting it from long format to wide format with pivot_wider() from the tidyverse.
co_na_h_votes_117_wide<-co_na_h_votes_117 %>%
pivot_wider(values_from = cast_code, names_from = rollnumber)Before continuing, take time to observe the structure of the data co_na_h_votes_117_wide in wide format, and think ahead to how the distance metric will handle missing values NA. For example, enter co_na_h_votes_117_wide %>% select(1:11) and observe that Buck has a missing NA value in roll call vote 10. In calculating the distances between the Representatives, all comparisons with Buck will ignore roll call vote 10. For all other distances between Representatives, across the 10 votes, each will be included in the distance calculation. Across all votes, if two Representatives have any NA values in the votes being compared, only that specific distance calculation involving an NA value will be excluded, with all others included. With the wide dataset, to prepare it for the distance calculations, next we move the name variable to the defined names of the rows (in place of numbered row names), which will be necessary for identifying the representatives in the measure of dissimilarity and then the output visualizations.
With the Representatives on row names and votes organized across columns, we can calculate and compare two different distance metrics, Euclidean and Manhattan:
The Euclidean distances are the following:
## LAMBORN_CO_R PERLMUTTER_CO_D BUCK_CO_R
## PERLMUTTER_CO_D 24.746
## BUCK_CO_R 12.960 26.880
## CROW_CO_D 24.551 3.335 26.755
## NEGUSE_CO_D 24.778 3.885 26.882
## BOEBERT_CO_R 14.645 27.845 11.121
## DeGETTE_CO_D 24.850 3.893 26.880
## CROW_CO_D NEGUSE_CO_D BOEBERT_CO_R
## PERLMUTTER_CO_D
## BUCK_CO_R
## CROW_CO_D
## NEGUSE_CO_D 3.755
## BOEBERT_CO_R 27.785 27.880
## DeGETTE_CO_D 4.266 2.837 27.831The matrix hints at the furthest ‘right’ Representative being Boebert, who is the most distant from Colorado Democrats. The Democrats have relatively close distances. Compare this matrix with the Manhattan distances:
## LAMBORN_CO_R PERLMUTTER_CO_D BUCK_CO_R
## PERLMUTTER_CO_D 612.371
## BUCK_CO_R 167.974 722.526
## CROW_CO_D 602.734 11.123 715.842
## NEGUSE_CO_D 613.945 15.091 722.630
## BOEBERT_CO_R 214.475 775.354 123.686
## DeGETTE_CO_D 617.499 15.152 722.526
## CROW_CO_D NEGUSE_CO_D BOEBERT_CO_R
## PERLMUTTER_CO_D
## BUCK_CO_R
## CROW_CO_D
## NEGUSE_CO_D 14.099
## BOEBERT_CO_R 772.029 777.291
## DeGETTE_CO_D 18.201 8.048 774.552Because the data includes NA values, the Manhattan distances are not whole numbers, distances with the scaling factor applied to each calculation. If calculated without the scaling factor, a Manhattan distance has an interesting interpretation. Since the Manhattan distance sums the absolute difference between each roll call vote scored 0 ‘nay’ and 1 ‘yea’, the unadjusted Manhattan distance counts the number of votes where two legislators differ. If two legislators cast a different ‘yea’ or ‘nay’ on 300 votes, their Manhattan distance would be 300.
We can compare the scaled up Manhattan distances with the distances calculated on the votes not containing any missing values, by selecting out each of those columns:
co_117_man_comp_distances <- co_na_h_votes_117_wide %>%
select_if(~ all(!is.na(.))) %>%
dist(method="manhattan")The line select_if() function is applied to a “formula” ~ all(!is.na(.)), selecting any column that does not contain a NA. The . dot refers to the current column select_if() is working through to find NA values — and selecting all that do not is.na(.) contain any NA values.
## LAMBORN_CO_R PERLMUTTER_CO_D BUCK_CO_R
## PERLMUTTER_CO_D 554
## BUCK_CO_R 146 644
## CROW_CO_D 545 9 639
## NEGUSE_CO_D 556 12 644
## BOEBERT_CO_R 188 694 110
## DeGETTE_CO_D 558 12 644
## CROW_CO_D NEGUSE_CO_D BOEBERT_CO_R
## PERLMUTTER_CO_D
## BUCK_CO_R
## CROW_CO_D
## NEGUSE_CO_D 13
## BOEBERT_CO_R 693 696
## DeGETTE_CO_D 17 8 694The distances, in whole numbers, measure the number of votes differing between each legislator. We will compare a one-dimensional representation of the voting similarity between the Euclidean and the unscaled up whole number Manhattan distances. First the Euclidean distances, storing the results in co_h_117_euc_mds:
Stress shows an excellent one-dimensional fit of .0027. (Type co_h_117_euc_mds$stress). We store the coordinates co_h_117_euc_mds$conf as a dataframe, apply and clean up the labels for each representative, then graph the result:
co_mds_df_euc <- as.data.frame(co_h_117_euc_mds$conf) %>%
rownames_to_column(var = "name") %>%
mutate(name = str_remove_all(name, "_CO")) In the second line, the row names are moved to a column; in the third, the name column is edited with str_remove_all() to find and delete each of the State identifiers “_CO”.
Then co_mds_df_euc is fed into ggplot(). We use ggrepel for the labels, like in the prior graphic. One change in the ggplot() is that in place of a variable for a second dimension, we specify y=0, since we want to visualize the points on a single dimension. The result appears in Figure 7.5, which show that the Democrats from Colorado voted more cohesively than the Republicans. Within the delegation, DeGette and Boebert had the most dissimilar voting records, and interpreting the distances in ideological terms both were the most liberal and conservative, respectively.
ggplot(co_mds_df_euc) +
geom_point(aes(x = D1, y = 0)) +
geom_text_repel(aes(x = D1, y = 0, label = name), max.overlaps = 7) +
labs(x = "Euclidean distance-based ordering of votes", y = " ") +
theme(axis.text.y = element_blank(),
axis.ticks.y = element_blank())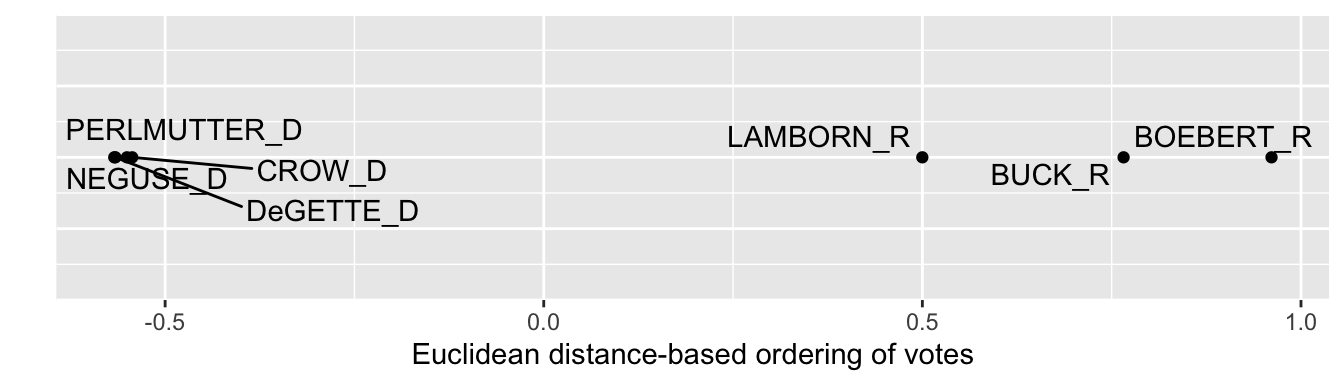
FIGURE 7.5: One-dimensional solution from multidimensional scaling of U.S. House roll call votes, Colorado delegation, 117th U.S. Congress, Euclidean distances.
We can compare the dimensional solution and visualization from the Euclidean distances with the whole number Manhattan distances that count up the number of differences in votes (‘yeas’ versus ‘nays’) between them. We would repeat the process used to find and graph the Euclidean MDS solution. While this code is not evaluated, in this example the Manhattan distances would provide a practically identical one-dimensional visualization.
co_h_117_man_mds<-mds(co_117_man_comp_distances, ndim=1, type="ordinal")
co_mds_df_man <- as.data.frame(co_h_117_man_mds$conf) %>%
rownames_to_column(var = "name") %>%
mutate(name = str_remove_all(name, "_CO")) Usually the dimensional graphics are visibly sensitive to the choice of distance metrics, although the general conclusions likely remain the same. And with only seven objects, a single dimension fits the data well given the low Stress value. Next, however, we will investigate votes in the U.S. Senate — all 100 Senators — and compare a one- and two-dimensional model fit. We’ll go back to the Senate data, and repeat the steps on the U.S. House data.
Scaling votes in the Senate
We start with the combined House and Senate data and select on the Senate chamber:
With the U.S. Senate votes saved in s_memb_votes_117, entering table(s_memb_votes_117$bioname)reveals that 949 roll call votes were taken, and that Vice President Harris cast two votes, along with temporary appointee from Georgia, Senator Loeffler. We will remove their two votes to limit the dataset to the elected Senators serving throughout the session of Congress.
s_memb_votes_117 <- s_memb_votes_117 %>%
filter(bioname != "LOEFFLER, Kelly") %>%
filter(bioname != "HARRIS, Kamala Devi")Then we follow the same steps from the House votes to form the name-party-State variable and encode the NA missing values for votes of ‘present’ and absences. One additional line is to change the last_name of each Senator to title case and to code the two independent Senators as “I” for party affiliation:
s_memb_votes_117<- s_memb_votes_117 %>%
separate(bioname, c("last_name", "first"), sep=", " ) %>%
mutate(last_name = str_to_title(last_name)) %>%
mutate(party_code = case_when(
party_code == 100 ~ "D",
party_code == 200 ~ "R",
party_code == 328 ~ "I")) %>%
unite(name, c("last_name", "state_abbrev", "party_code")) %>%
select(-first, -icpsr) %>%
mutate(cast_code = case_when(
cast_code %in% c(5, 10) ~ NA,
TRUE ~ cast_code))Inspect s_memb_votes_117 to observe it matches the format of the House data. Next we pivot the data to wide format (saving it as s_memb_votes_117_wide) and move the name column to the row names of the data table to feed into the mds() function.
s_memb_votes_117_wide<-s_memb_votes_117 %>%
pivot_wider(values_from = cast_code, names_from = rollnumber) The data is pivoted, then we move the name column to the row names:
Inspect the data table s_memb_votes_117_wide to verify it matches the structure of the House votes data to create the distances. We will create a matrix of Euclidean distances, stored as s_117_euc_distances.
Like the House distance matrix, this matrix is calculated from each roll call vote without any ‘present’ or ‘absences’. The distance object is too large to view as a whole, but to observe part of it, we can convert it to a matrix and view the first few columns and rows:
## Tuberville_AL_R Shelby_AL_R
## Tuberville_AL_R 0.000 8.811
## Shelby_AL_R 8.811 0.000
## Murkowski_AK_R 22.538 21.216
## Sullivan_AK_R 12.832 12.408
## Sinema_AZ_D 28.611 27.772
## Murkowski_AK_R Sullivan_AK_R
## Tuberville_AL_R 22.54 12.83
## Shelby_AL_R 21.22 12.41
## Murkowski_AK_R 0.00 19.75
## Sullivan_AK_R 19.75 0.00
## Sinema_AZ_D 18.01 26.13
## Sinema_AZ_D
## Tuberville_AL_R 28.61
## Shelby_AL_R 27.77
## Murkowski_AK_R 18.01
## Sullivan_AK_R 26.13
## Sinema_AZ_D 0.00## [1] 0.0243The one-dimensional solution Stress is .024, suggesting a one-dimensional structure fits the pattern of ‘yeas’ and ‘nays’. Next we convert it to a dataframe, bringing the row names to a column, then graphing it with ggplot():
Figure 7.6 visualizes the structure. Along a single dimension, Democrats are more closely clustered together, apparently voting with greater party discipline, than are Republicans. The geom_text_repel() function labels observations where a given label fits, in this case pointing out the Republicans with more moderate voting records based on similarity of roll call votes. Inspect the individual scores for each Senator with s_117_euc_mds %>% arrange(D1).
ggplot(s_117_euc_mds) +
geom_point(aes(x = D1, y = 0)) +
geom_text_repel(aes(x = D1, y = 0, label = name)) +
labs(x = "Euclidean distance-based ordering of votes", y = " ") +
theme(axis.text.y = element_blank(),
axis.ticks.y = element_blank())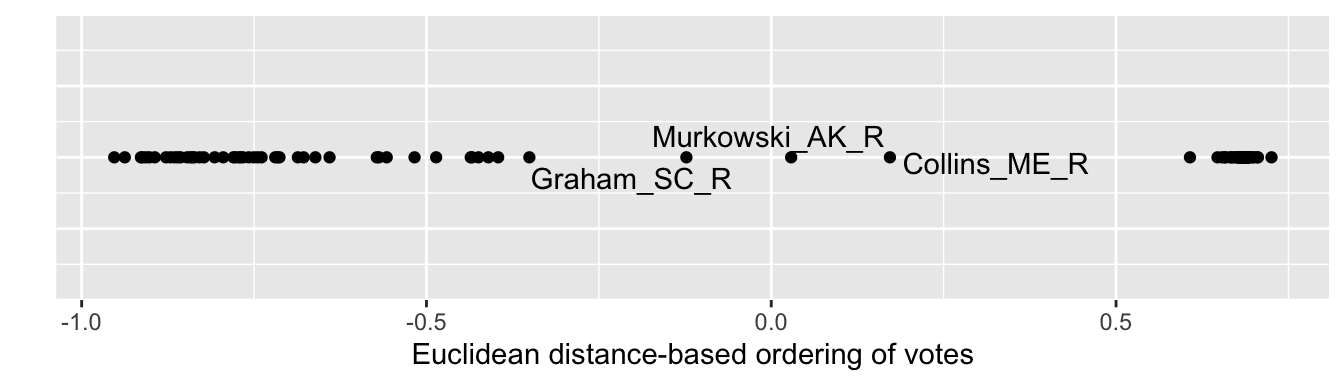
FIGURE 7.6: One-dimensional solution from multidimensional scaling of U.S. Senate roll call votes, 117th U.S. Congress, Euclidean distances.
We will investigate whether a two-dimensional representation provides any insight into voting patterns. We calculate the scores for each Senator on the two dimensions:
## [1] 0.02038The Stress improves only a negligible amount, suggesting little improvement in fit over two dimensions. We create the dataframe, and then feed it into ggplot() for the visualization.
Figure 7.7 depicts the two-dimensional MDS structure of roll call votes in the Senate. As in the last figure, the tick marks and numerical scaling are excluded with the code within theme(), to avoid giving the impression that the numeric scores have an underlying meaning tied to the points.
ggplot(s_117_euc_mds2) +
geom_point(aes(x = D1, y = D2)) +
geom_text_repel(aes(x = D1, y = D2, label = name)) +
labs(x = "Dimension 1", y = "Dimension 2") +
theme(axis.text.x = element_blank(),
axis.ticks.x = element_blank())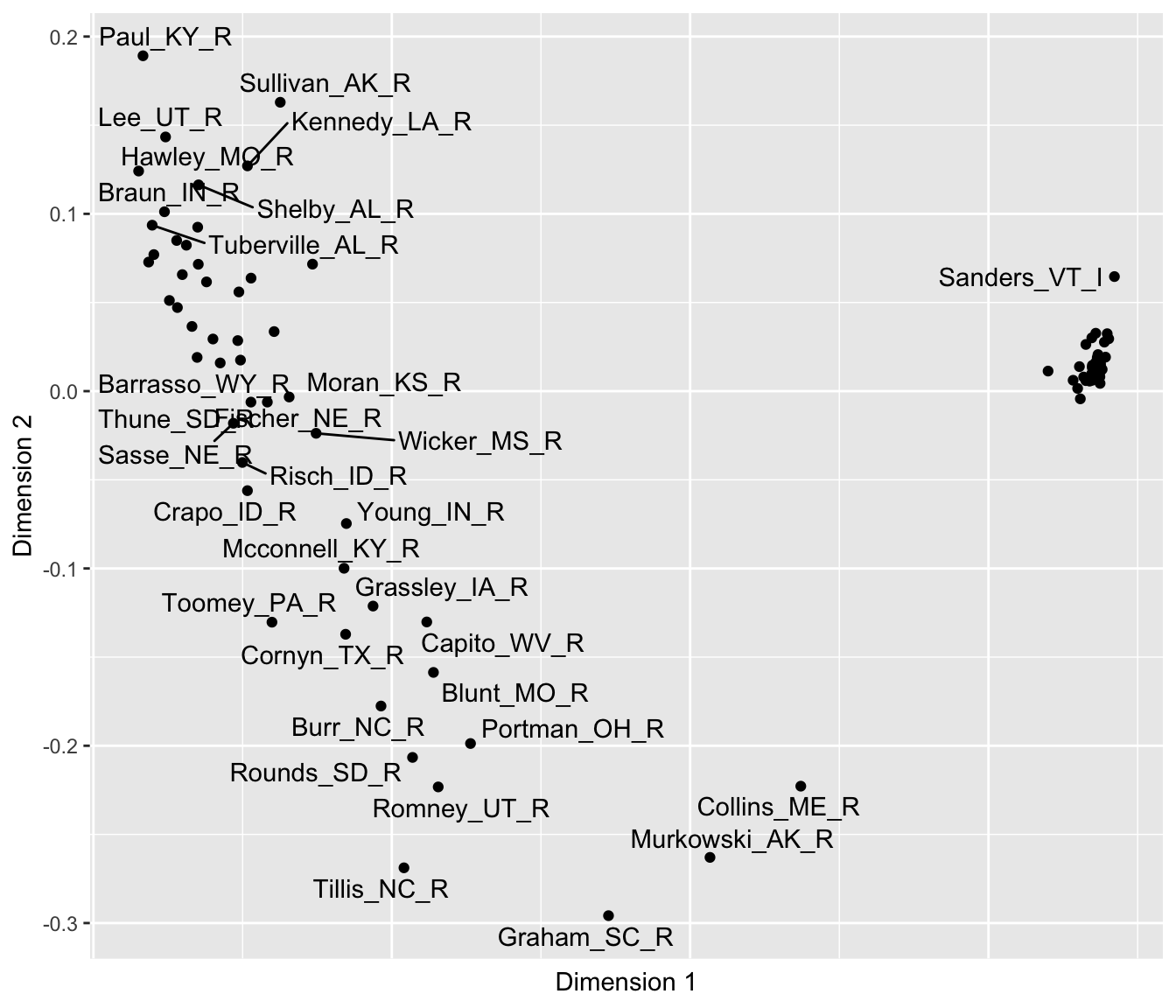
FIGURE 7.7: Two-dimensional solution from multidimensional scaling of U.S. Senate roll call votes, 117th U.S. Congress, Euclidean distances.
## List of 2
## $ axis.text.y : list()
## ..- attr(*, "class")= chr [1:2] "element_blank" "element"
## $ axis.ticks.y: list()
## ..- attr(*, "class")= chr [1:2] "element_blank" "element"
## - attr(*, "class")= chr [1:2] "theme" "gg"
## - attr(*, "complete")= logi FALSE
## - attr(*, "validate")= logi TRUEThe two-dimensional results clearly show the same left to right difference observable on Dimension 1, with Collins, Murkowski, and Graham having the more centrist voting record along it. The two Senators Hawley and Sanders anchor both ends of the dimension. And of course the close clustering of Democrats reveals a high degree of party unity in voting, perhaps to be expected given their slim majority. And like the first, the second dimension shows distinct differences among Republicans. On this second dimension, Graham anchors the bottom of the figure, followed by Tillis and Murkowski. Perhaps this dimension reflects a willingness to vote against the party leadership. Of course, the interpretation of the dimensions is necessarily impressionistic and somewhat subjective, and the arrangement of the points is dependent on the votes and the chosen distance metric. In presenting MDS results, researchers typically investigate the sensitivity of the results to the chosen metric.
7.5 Clustering feelings and votes
The term “Cluster analysis” refers to a wide range of analytical methods. Like MDS, it relies on distance metrics as a data input. Unlike MDS, however, rather than uncover a dimensional structure of the data, the purpose is to identify clusters or groups of similar political phenomena. A common approach to cluster analysis is hierarchical agglomerative clustering (HAC) (Bartholomew et al. 2008), which is reviewed conceptually below.
Cluster analysis, like MDS, starts with a matrix of distances to begin identifying clusters. The typical end product of a cluster analysis is a specific visualization, a dendrogram, which displays the formation of clusters in a hierarchy of similarity.
The ‘agglomerative’ term means that the clustering process is bottom-up, starting with the maximal number of clusters, then ending up with all observations combined into one cluster. The HAC algorithm proceeds in a series of steps: (1) each observation begins as its own cluster; (2) the algorithm merges the two closest clusters; (3) clusters become larger and are merged until all observations belong to a single cluster. The process of forming clusters yields overarching, ‘hierarchical’ clusters as the name implies.
The algorithm’s search for clusters requires specific rules for how it should join clusters together. At each step of the clustering process, the input distance matrix is reduced and recalculated among the clusters. The rules are often one of the following: “Single linkage”: the distance between the two closest points in different clusters, “Complete linkage”: the distance between the two farthest points in different clusters, or “Average linkage”: the average distance between all pairs of points in two clusters. The rule for combining clusters determines how clusters are formed, so the results of any cluster analysis are sensitive to the type of linkage used; for an illustration of different linkage effects, see Gareth et al (2013).
Hierachical AC is implemented with the hclust() function from the base R. The default linkage method is the complete linkage. To illustrate the interpretation of the analysis output, the dendrogram, we will start with the Colorado congressional votes. Given the Colorado matrix of Euclidean distances co_mds_df_euc, a HAC is:
##
## Call:
## hclust(d = co_117_euc_distances)
##
## Cluster method : complete
## Distance : euclidean
## Number of objects: 7The dendrogram
The results in hac show that the default complete linkage method was used; alternatives are specified with the argument method=, such as method="single" or "average". The output is the dendrogram, accessible with the plot() function:
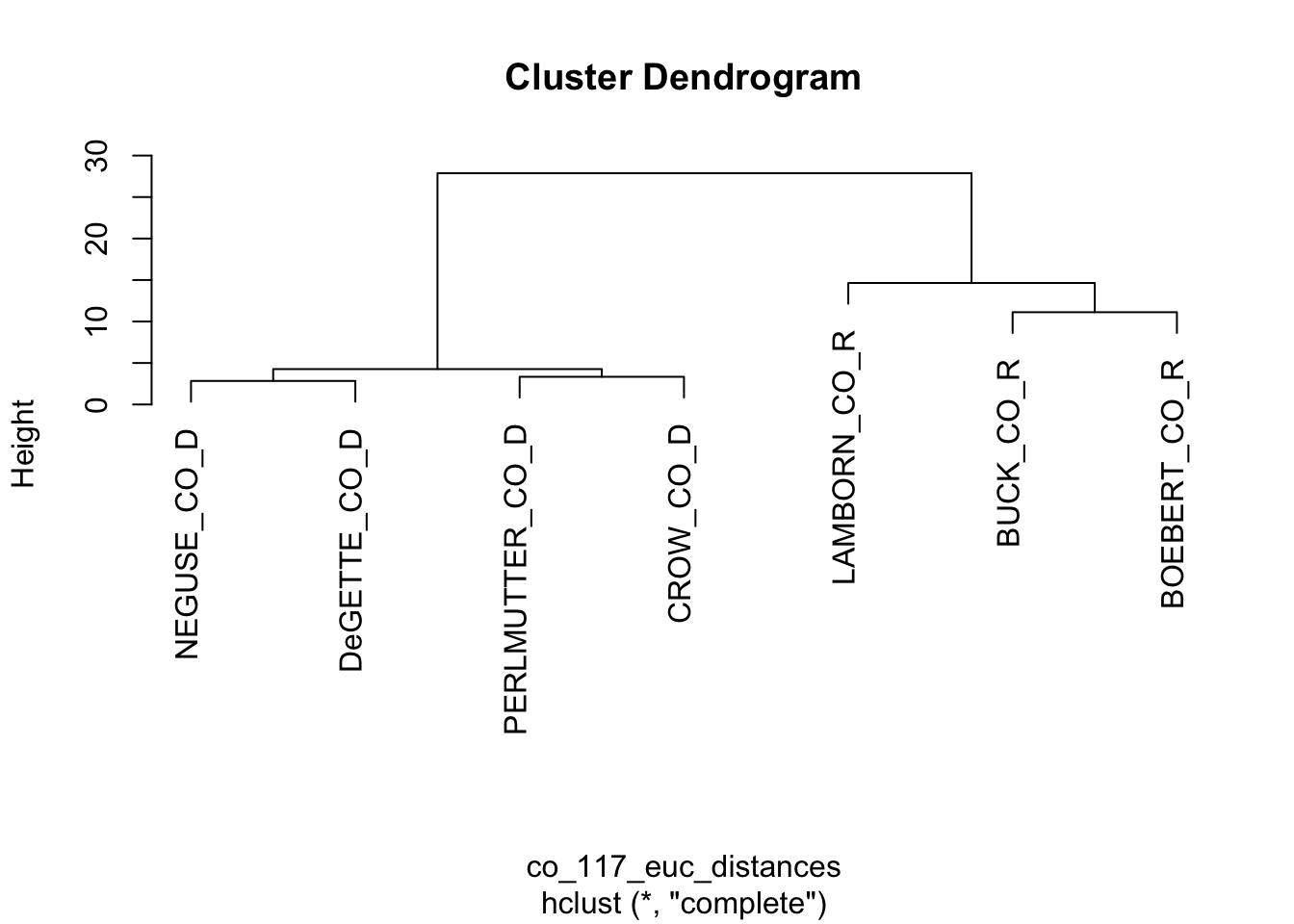
FIGURE 7.8: Dendrogram based on the Euclidean distance matrix of roll call votes cast by the Colorado delegation.
Figure 7.8 displays the resulting dendrogram. The diagram resembles a tree, with branches showing the sequence of cluster formations from pairs to larger group formations. The vertical axis labeled “Height” refers to the distances at which the clusters merge; clusters joined together in branches at higher levels of height are less similar. At the bottom of the figure, the labels or ‘leaves’, show that at first, the algorithm identified pairs such as Neguse and DeGette, and given the odd number of representatives, one singleton, Lamborn. Then in the next stage the algorithm clustered the four Democrats, then the three Republicans. The dendrogram provides a visual representation of similarity, while forming hierarchically larger (and less similar) groups.
To illustrate a more complex dendrogram, apply the hclust() function to the set of full Senate distances, s_117_euc_distances.
##
## Call:
## hclust(d = s_117_euc_distances)
##
## Cluster method : complete
## Distance : euclidean
## Number of objects: 100Plotting a legible dendrogram with 100 objects is not feasible as a small figure on a printed page. Try plotting it and adjust the size to make the labels visible, plot(hac_s). Like any other data visualization in R, there are endless ways to customize the appearance of a dendrogram; packages to do so are reviewed at the end of the chapter. Figure 7.9 displays a dendrogram with smaller text labels for the leaves, a suppressed title, and manually rotated, plot(hac_s, cex=.5, main=NULL, xlab=" ").

FIGURE 7.9: Dendrogram displaying the clusters of U.S. Senators in the 117th Congress, based on Euclidean distances of roll call votes.
The Senate dendrogram provides a contrasting view of the patterns of roll call votes. Unlike the MDS output, there is no underlying order, beyond similarity within pairs and the increasing hierarchy of larger clusters. Senators Murkowski and Collins pair together, and have a voting record dissimilar enough from other Senators that they are joined by Graham only in later state of clustering after other Senators have been paired into groups of a dozen or more. The party caucuses are divided in two, joined together only in the last stage of the clustering algorithm. Take some time to reflect on other aspects of the dendrogram that interest you.
General steps in scaling and clustering
A scaling and clustering analysis starts with a chosen dissimilarity matrix. While there is no one correct distance metric, different input metrics lead to different outputs. In the examples reviewed in this chapter, each of the measures forming the input matrix are on the same scale (0 - 100 degrees; 0 or 1), but in other cases where measures differ widely, standardization may be necessary. And some consideration should be given to the tradeoffs between the characteristics of different distance metrics given the research question (James et al. 2013). Next, decide on the number of dimensions for the MDS solution. Since the goal of the analysis is a visualization, usually researchers find arrangements for one or two dimensions, while checking the Stress statistic to observe how well the configuration represents the data. Once you have run the MDS algorithm, interpret the resulting configuration by focusing on the relative distances between points: look for spaces, clusters, and directions of points. Are there readily apparent clusters; which observations comprise the clusters, and what do the clustered observations have in common? Keep in mind that the axes in an MDS plot do not have an inherent meaning, and neither do the exact scores of the points on each axis. Assess whether the MDS solution aligns with theoretical expectations or reveals meaningful patterns; in writing up results, include fit statistics and a sensitivity analysis. In a cluster analysis the linkage method affects the formation of clusters, so researchers often try multiple linkage methods to observe how clusters form differently in a dendrogram.
Resources
The package unvotes (Robinson 2021) organizes votes of member states in the United Nations; the same analyses presented in this chapter could be applied to study patterns of country-level voting.
The wnominate (K. Poole et al. 2024) package estimates the ideological scores from roll call votes described in this chapter from Voteview.com. It could be applied to votes from unvotes or any legislative body.
As explanatory visualizations, dendrograms are frequently ‘pruned’ (such as excluding one or two branches) or customized. Popular packages for customizing dendrograms include dendextend (Galili 2015) and ggdendro (Vries and Ripley 2021).
7.6 Exercises
Knit your R code into a document to answer the following questions:
Using the polfigures.csv data, re-create the two-dimensional representation of the figures (and social groups) using Manhattan distances. How does the different metric change observations about the arrangement of figures and groups in the two-dimensional space?
Using poll_ft.csv, subset the data to just the feeling thermometer scores on social groups, with a command such as
socialgroups<-poll[,c(21:39)], limiting the data table to only social group feeling thermometers. Using this subsetted data,socialgroups, usemds()to represent the differences in group feelings within a one-dimensional space. How would you interpret the resulting arrangement of the figures?Import the polfigures_ft.csv dataset, and create a one-dimensional figure based on Manhattan distances with MDS. Explain the code, each step in the analysis, and interpret the resulting figure.
Pick a U.S. State with a relatively large delegation to the U.S. House of Representatives. Subset the 117th US Congress roll call voting data to this State and the House delegation. (If you have not already, you will need to download the original raw data from Voteview.com and follow the steps to tidy and subset the data.) Using cluster analysis, create a dendrogram visualizing similarity in voting across the delegation. Try an alternative linkage method to the default. Explain the steps to create the dendrogram, and interpret the results.
Create a distance matrix on characteristics of the four country-level components of the Human Development Index in the file hdi_2021.csv and visualize it. To construct the distance matrix, use the
scale()function to create standardized z scores for each variable, prior to applyingdist(). How do you interpret the figure?